May 26, 2026
Cerebras inference is very fast. So fast that it changes how we think about configuring our LLMs for voice agent use cases.
Kimi K2.6 is a 1T parameter reasoning model that @cerebras serves at 650 - 1,000 tokens per second (end-to-end throughput), with time to first token metrics as low as 150ms (latency).
These numbers are two to three times faster than other similarly capable models.
The biggest lever we get from this kind of speed is that we can use the model in reasoning mode, and still have excellent "time to first non-thinking token."
This solves a big pain point we have in 2026 for voice agent use cases. Almost all recent innovation in post-training has focused on making models good at reasoning ("test time compute"). This is great, but it makes the user-facing model latency much, much slower. Which is a problem for conversational voice agents.
We can run Kimi K2.6 with reasoning turned on, and get responses faster than other models produce with reasoning disabled.
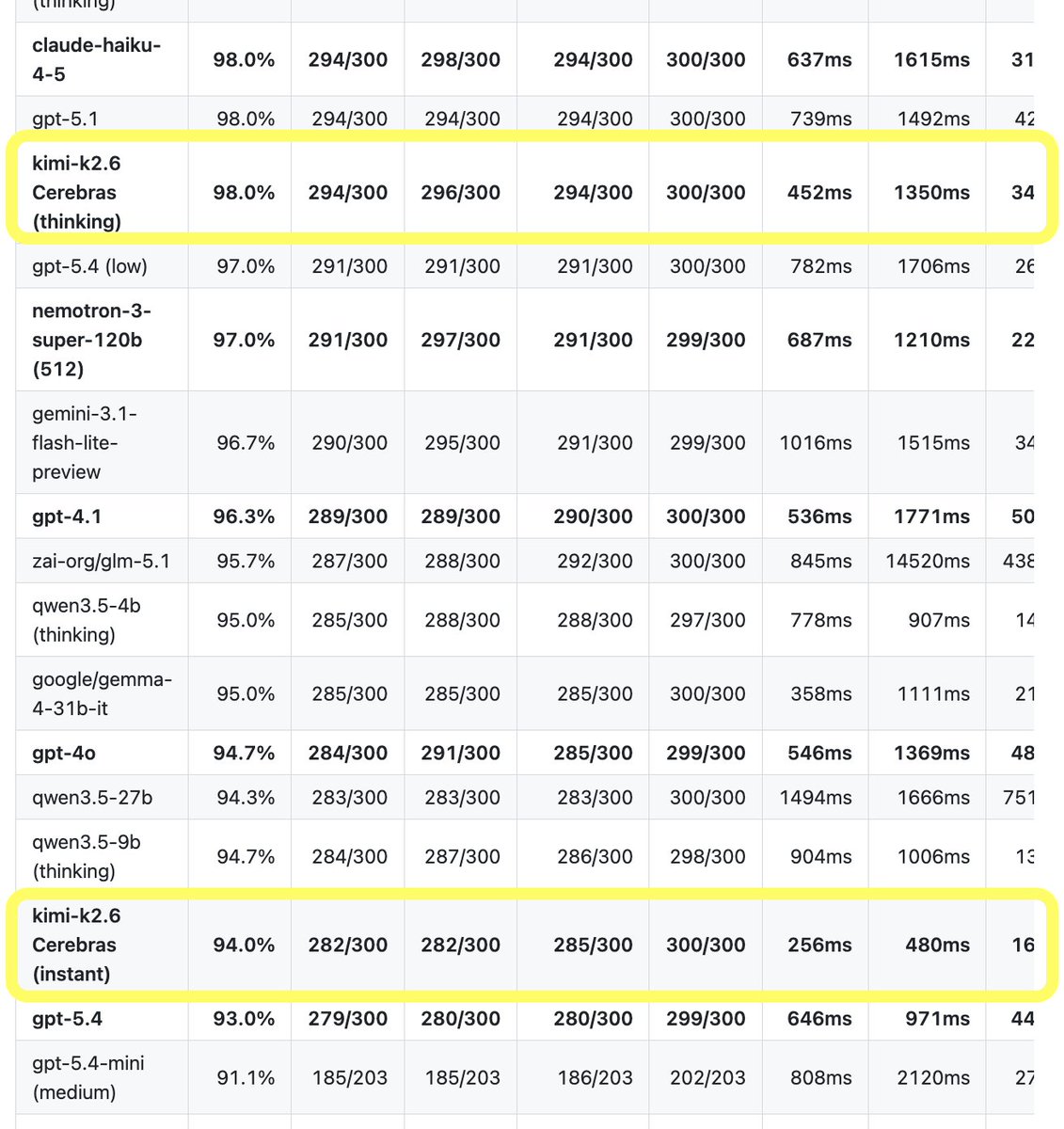
On my 30-turn voice agent benchmark, Kimi K2.6 with reasoning enabled ties GPT 5.1 and Haiku 4.5 with reasoning disabled, and is still about 200ms seconds faster!
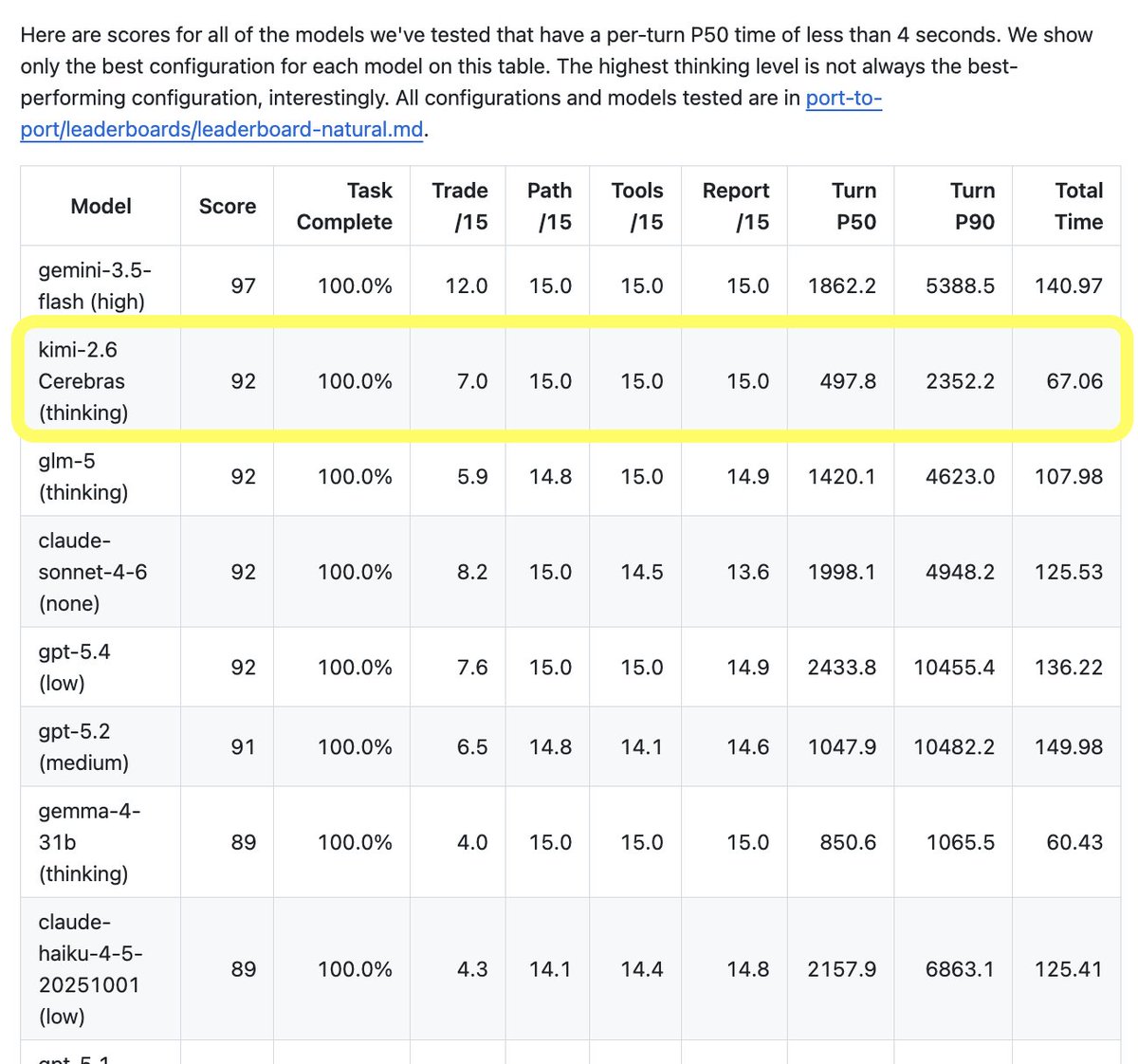
On my primary task agent benchmark, Kimi K2.6 is now the #2 model. It ranks just behind Gemini 3.5 Flash in "high" reasoning mode, and tied with GLM 5, Sonnet 4.6, and GPT 5.4 with reasoning set to "low." But Kimi K2.6 completes each turn in the agent loop in under 500ms. The other four models are all at least 3x slower. (Models only qualify for this benchmark if they can complete task turns at a P50 <4s.)
A couple of other things that this speed buys us, for production voice agents:
- Tool calls happen fast enough that we don't have to work around tool call latency in our pipeline design.
- We can prompt the model to output structured data at the beginning of a response, followed by plain text for voice generation. This opens up possibilities like asking the model to do complex classification/generation tasks that influence the rest of the pipeline. For example, the model could create a detailed style prompt for a steerable TTS model, for each individual conversation turn.
And, of course, you can use Kimi K2.6 with reasoning turned off. Cerebras calls this "instant" mode.
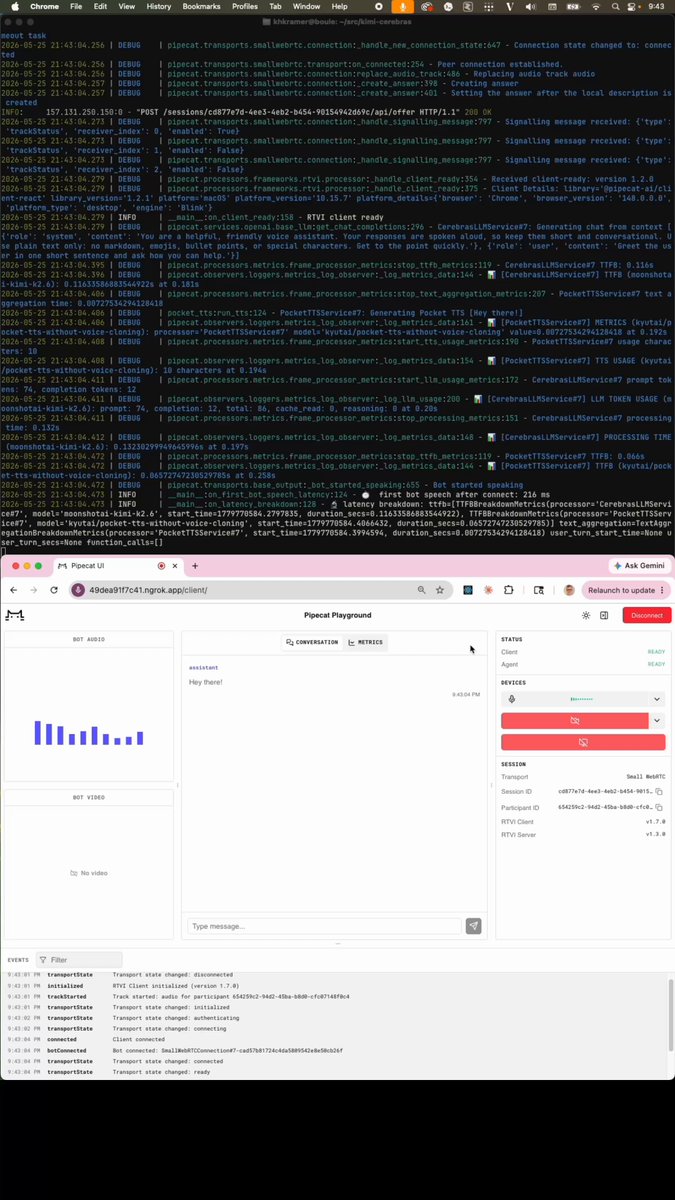
Here's a video of a Cerebras Kimi K2.6 voice agent with voice-to-voice response time, measured at the client, under 500ms. This is the true response latency as perceived by the user, including all network and audio codec overhead, transcription and turn detection, Kimi K2.6 token generation, and voice generation. 500ms is, effectively, instant. So the Cerebras naming for this mode is a propos. :-)
See the Cerebras blog post about Kimi K2.6 for more notes about the model: https://t.co/2PJWbP5oP0
Benchmark results are uploaded here:
- https://t.co/EPMF7fwVaw
- https://t.co/wkN0AI9OQS
The voice agent in the video is just a standard Pipecat pipeline using:
- Pipecat native audio Smart Turn - https://t.co/urWVrzYZ68
- NVIDIA Nemotron ASR Streaming - https://t.co/0ajndKpVb8
- Cerebras Kimi K2.6
- Kyutai Pocket TTS - https://t.co/0LVgclv814
You can use the Pipecat CLI to create an agent like this, including the peer-to-peer WebRTC network transport and the developer UI in the video.
https://t.co/fpEtdb31sp