May 7, 2026
OpenAI shipped a new speech-to-speech model today: gpt-realtime-2
This is the first speech-to-speech model good enough to use in my voice agents that do "real work."
Or real play, for that matter. Here's gpt-realtime-2 as the brain of the ship AI in Gradient Bang.
The voice-to-voice response and tool calling times here are unedited, so you can see exactly what the interaction with the model is like in an agent with a very complex system instruction and frequent tool calls.
(I did clip out the subagent task execution segments, after gpt-realtime-2 starts a subagent via a tool call. Subagents in this config used gpt-5.2 "medium" effort.)
I have a lot of benchmarks and tests for voice agents.
Being the "brain" for Gradient Bang is an excellent, very hard, test for today's models. The ship AI agent implementation is complicated:
- 25 tool definitions
- a large system prompt (~8k tokens)
- structured data events are injected in large volume from the game server
- context sharing with task subagents
- situational inference triggering
- async context compression
- a UI with streaming text display and bi-directional sync with model state
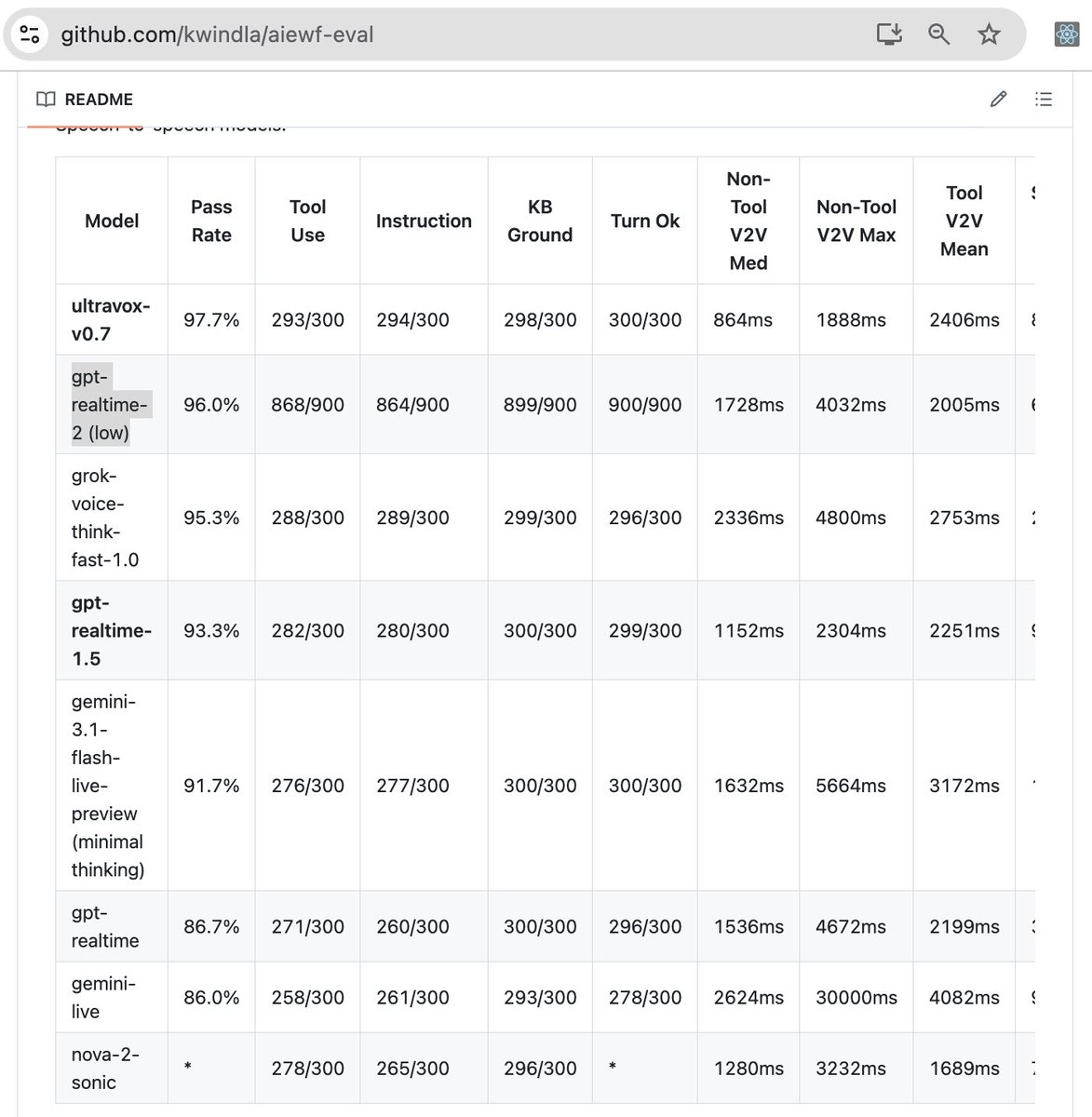
Here is gpt-realtime-2's performance on the aiewf-eval benchmark.
This new model is now the best-performing fully speech-to-speech model.
(Ultravox is a native audio input model that outputs text. The Ultravox API is a very well-engineered speech-to-speech multi-model system.)
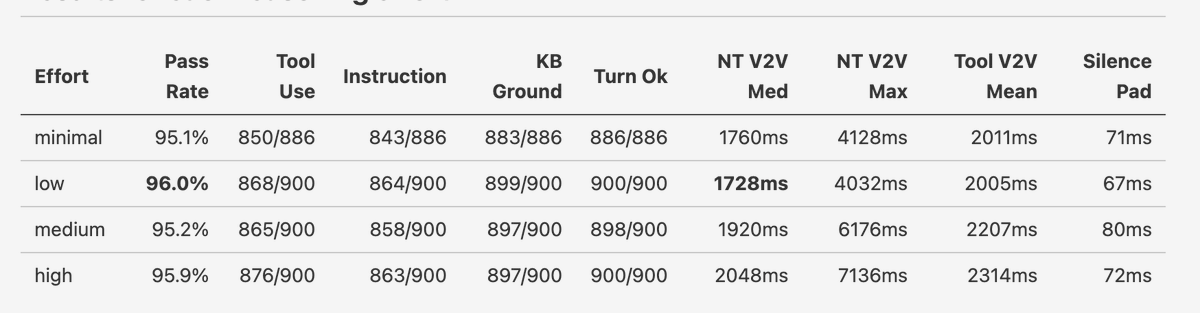
The model supports four reasoning effort levels. Here are the aiewf-eval results for each reasoning effort.
The sweet spot is "low", which, on this benchmark, actually performs better than higher reasoning levels.
This is a pattern we see fairly often on our complex, long multi-turn, agentic task benchmarks. The highest reasoning efforts don't always score the best. Possibly AI models, like humans, sometimes think themselves into sub-optimal decisions!
Codex implemented the gpt-realtime-2 support in the Gradient Bang voice agent code. It did a good job!
Here's the PR. This is still a work in progress because mostly I told Codex to implement compaction as a phase 2 feature, and I haven't gone back to the terminal to kick that off.
There also may be a bug in tool call handling or inference triggering timing in my (very complicated) pipeline. You can see in the video that the voice agent interrupts itself once, while it's planning a task. I need to track that down.
PR link: https://t.co/2F7UeKqSad
Here's the official OpenAI announcement post for the new model:
[1]
Congratulations to the OpenAI Realtime team!