May 1, 2026
Local native-audio voice agent running on an RTX 5090.
- @NVIDIAAI Nemotron 3 Nano - audio|text ➡️ text
- patched vLLM to implement complete turn prefix caching
- ~125ms TTFT
- @kyutai_labs Pocket TTS - text ➡️ audio
- Nemotron Speech ASR - streaming audio ➡️ text
- @pipecat_ai Smart Turn end-of-utterance
- ~500ms total voice-to-voice latency
- runs bash via tool calls
If you're interested in voice and realtime multi-modal AI, come join us at the SF Voice AI Meetup on Thursday May 7th. Talk to engineers from NVIDIA, Kyutai, and Pipecat about what you're building!
Links to meetup registration, code, and models on @huggingface below ...
Meetup registration[1]
Nemotron 3 Nano Omni[2]
Pocket TTS[3]
Smart Turn v3[4]
Complete code[5]

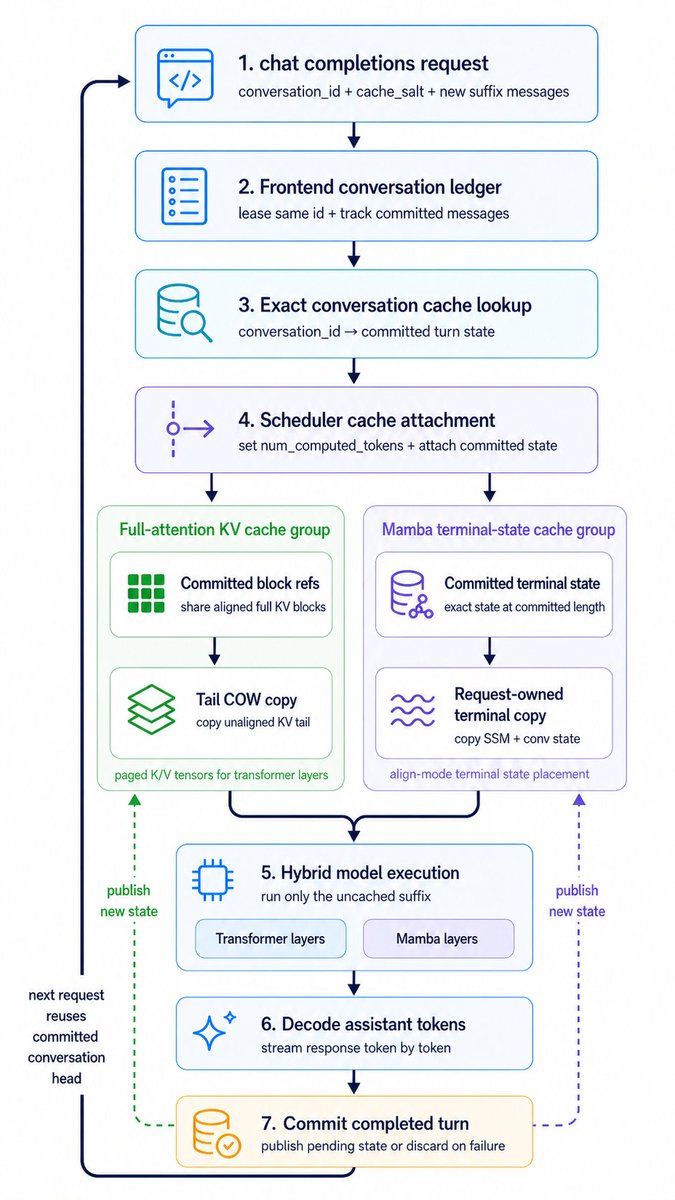
Prefix caching is very important for latency. But it's a little bit tricky to implement prefix caching for the Nemotron hybrid Mamba-Transformer Mixture-of-Experts (MoE) architecture.
vLLM doesn't have prefix caching (yet) for this model. The blocker is that vLLM's prefix caching machinery aims to be very general and flexible, with partial prefix matching to support use cases like system instruction re-use and conversation branching. Matching arbitrary prefix lengths conflicts with the design of the Mamba layers. Mamba operates on a compressed "recurrent" state rather a per-token KV state, so re-using state from an arbitrary-length prefix boundary doesn't work.
But we know exactly the use case we want to support: very fast continuation of our multi-turn voice conversation. Because vLLM and the Nemotron models are completely open source, we can just directly implement the cache logic we need.
Nemotron 3 Nano on RTX 5090 is very fast. Thanks to the caching, we get ~125ms TTFT for any context length that can fit in GPU memory.
Here's the code: https://t.co/HW5FbxnLIm
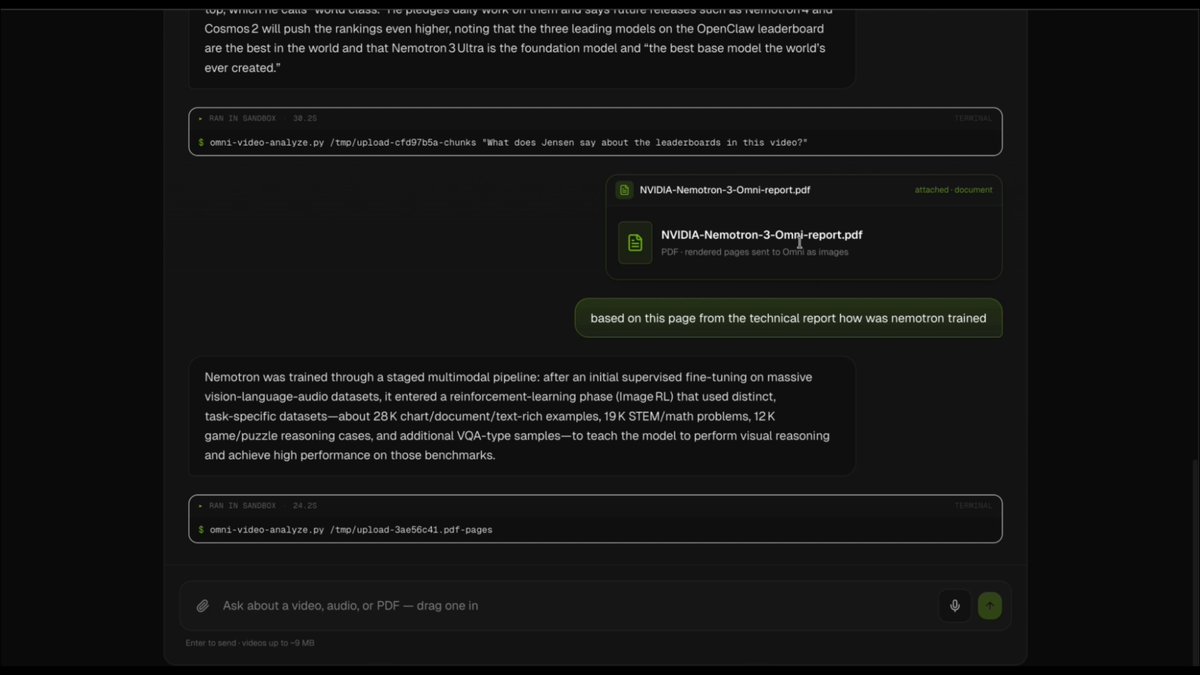
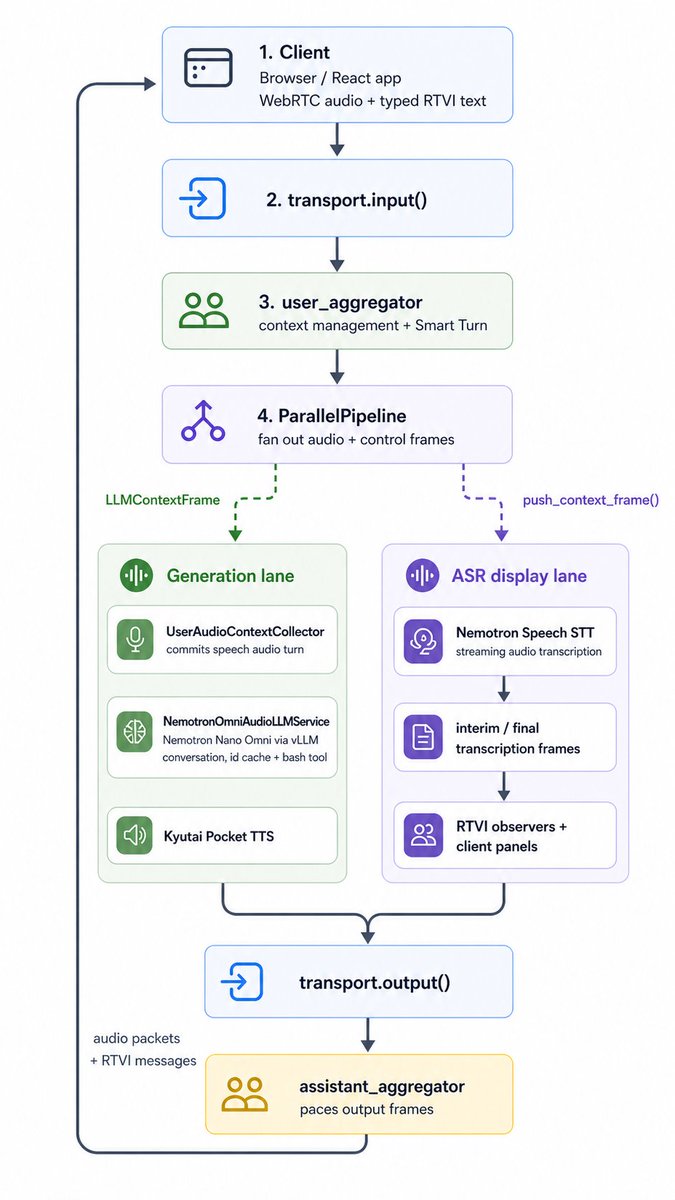
The voice agent is a self-contained Python file that implements a @pipecat_ai pipeline, plus a couple of small, custom Pipecat services for interacting with the locally running Nemotron and Pocket TTS models. We're running Pocket TTS on CPU to save GPU memory for LLM context. Pocket TTS is fast on CPU!
We use Nemotron Speech ASR, a very fast transcription model, to stream transcription to the client. Seeing what you're saying, in real time, is a nice UX element. Pipecat supports this in the standard voice-ui-kit front end library.
Here's what the heart of the agent code looks like, plus a diagram showing the data flow from the web client, through the Pipecat pipeline, and back.
The code here supports voice audio and text from the client to the server, and voice audio, text, and tool call information from server to the client.
No project is ever finished! The obvious next thing to add is image and video from the client to the server, and image, video, and arbitrary audio from the server to the client. Nemotron 3 Nano Omni can write bash code, and bash can use tools on the machine to fetch and generate images, audio, and video!
Pipecat open source voice-ui-kit library: https://t.co/pTZViwTur9

Here's @llm_wizard's video tour of the new Nemotron 3 Nano Omni model's multi-modal features:
https://t.co/AEL3jCNuG2
Meet Nemotron 3 Nano Omni 👋
Our latest addition to the Nemotron family is the highest efficiency, open multimodal model with leading accuracy.
30B parameters. 256K context length. 🧵👇