March 7, 2026
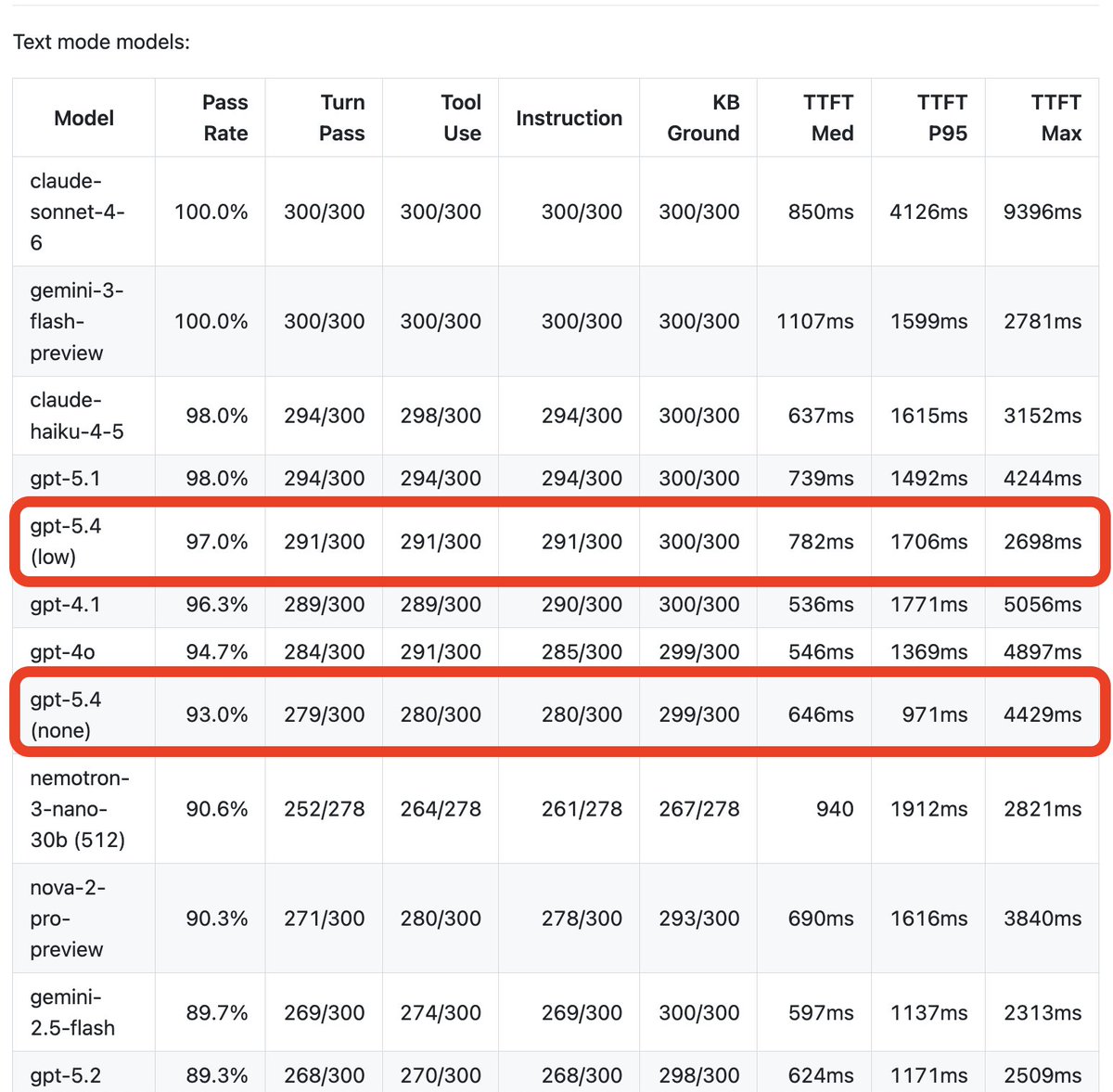
I'm super impressed with GPT-5.4 for general use and for coding.
I'm also a tiny bit disappointed (though not surprised) that it's not a standout model for voice agent use cases.
- reasoning_effort = none | performs slightly worse then GPT-4o
- reasoning_effort = low | performs slightly worse then GPT-5.1
("medium" and "high" reasoning_effort are too slow for most voice agent use cases.)
Every token the model generates adds to latency. And for voice agents, we have pretty hard latency caps. We need a TTFT of less than 700ms. (The actual content TTFT; the first post-thinking token!)
I've had a similar conversation with several teams training models recently: I totally understand the focus on RL for reasoning. The models are getting really good at some very hard things. But ... I think we could also keep improving some capabilities in low-reasoning configurations.
In particular, most new models are not very good at tool calling with reasoning turned off or set very low.
My intuition from doing just enough ML work to be over-confident about my knowledge is that we should be able to have our cake and eat it too, and that this is just a data sets and engineering focus issue. Today's model's could and should be better at low-thinking budget tool calling than last year's models, while still having all the higher thinking budget gains that are so impressive.
Open source benchmark code. (You should be able to reproduce the numbers in the screenshot I posted.)