February 23, 2026
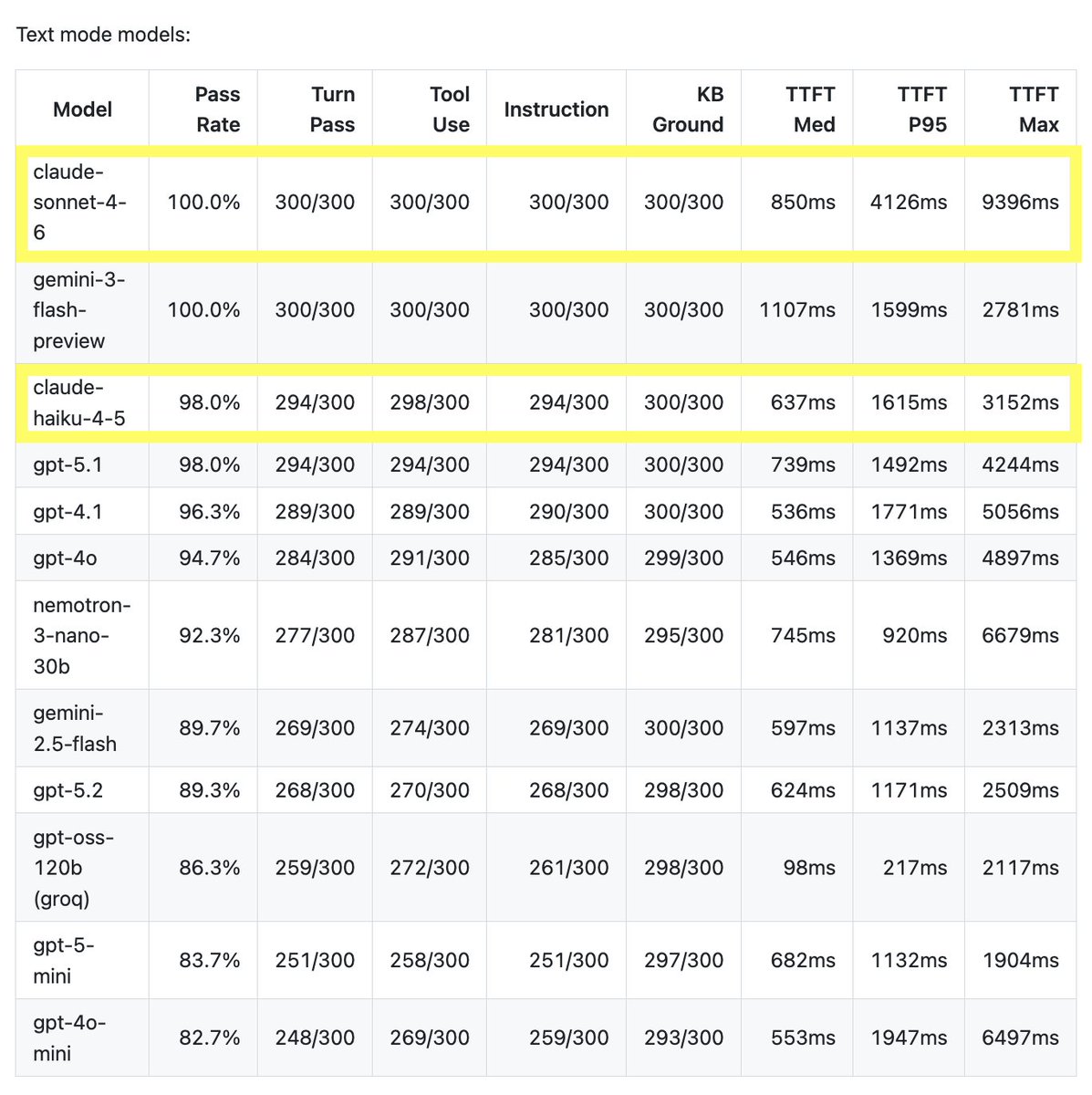
Claude Sonnet 4.6 scores 100%, with a median TTFT of 850ms, on our standard LLM Voice Agent performance benchmark.
It's currently the fastest model that saturates this benchmark.
I also re-ran the numbers for the whole leaderboard, and Claude Haiku 4.5 scored 98% with a TTFT of 637ms. This puts Haiku in front of GPT 5.1 in the rankings, and a bit better in "intelligence" than GPT 4.1, but 100ms slower.
This is the first time we've had an Anthropic model that's a really good fit for most of our voice agent use cases. And now we have two!
Claude models have always had great instruction following, tool calling, and conversational dynamics. But they've been slower than the other SOTA models. That's changed.
One reason to re-run a benchmark like this is that latency changes. We continuously monitor latency for all the models we regularly use. But a specific run of a long-format benchmark like this is a bit different than our standard monitoring.
Another reason, though, is that models like Claude, Gemini, and the GPT family are hosted systems and they evolve. A good rule of thumb is that changes in model behavior are probably your own code rather than real changes on the provider side. But that's not always true. And this performance jump for Claude Haiku 4.5 over the past two months is dramatic.
I recently fixed some corner cases in tool call handling and improved the judging prompts in this benchmark. So I'll re-run Claude Haiku 4.5 against the benchmark code from 2 months ago, at some point, because I'd like to understand whether I previously had bugs that unfairly penalized Haiku. But either way, whether the model has gotten better or we've ironed out some issues with the benchmark, Haiku is impressive and is worth experimenting with if you are a voice AI developer.
Benchmark code is here[1]
If you're building voice agents, realtime multi-modal AI systems, or are interested in benchmarks, we're talking about all three topics at this month's voice AI meetup on Thursday. Come hang out with us in-person in San Francisco…