February 14, 2026
Spending valentine's day exactly as you'd expect. (Arguing, politely, on LinkedIn about how to accurately measure latency and word error rates.) https://t.co/iULMyNZtNE
Wake up, babe. New Pareto frontier chart just dropped.
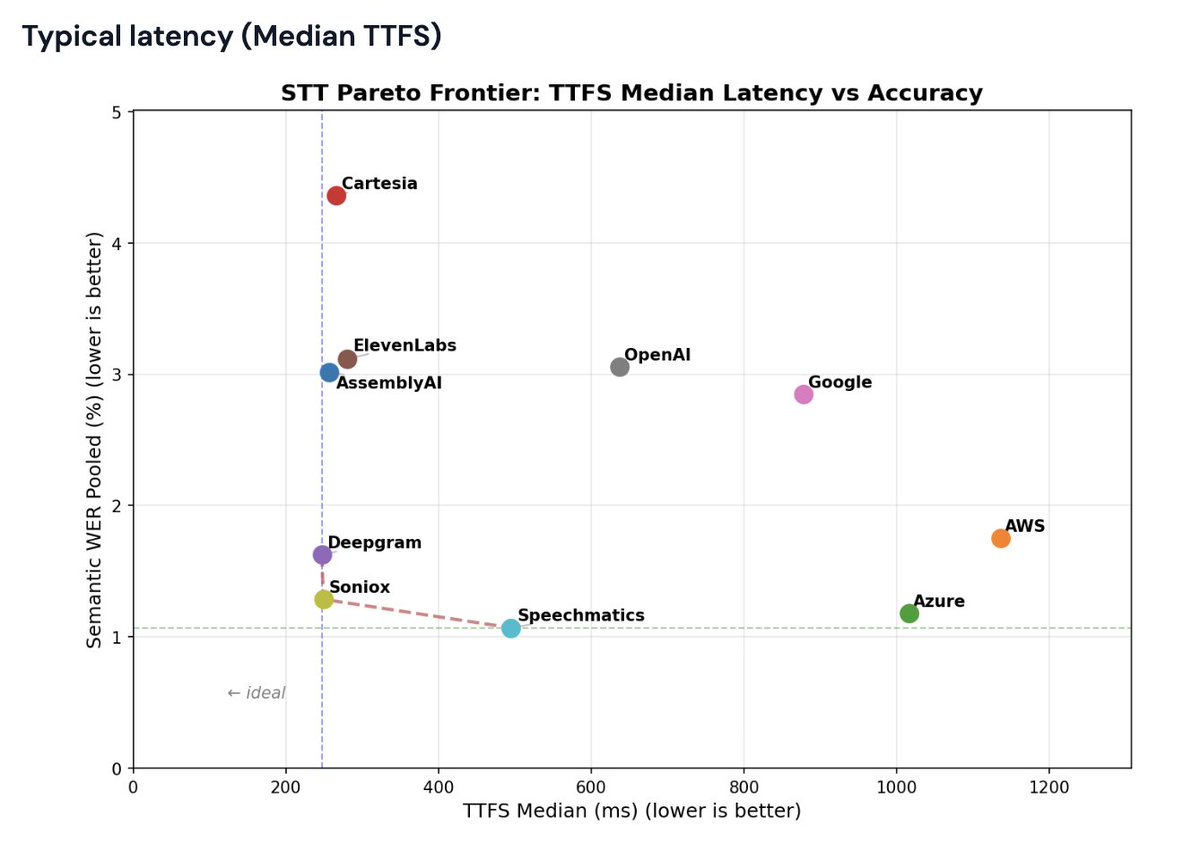
Benchmarking STT for voice agents: we just published one of the internal benchmarks we use to measure latency and real-world performance of transcription models.
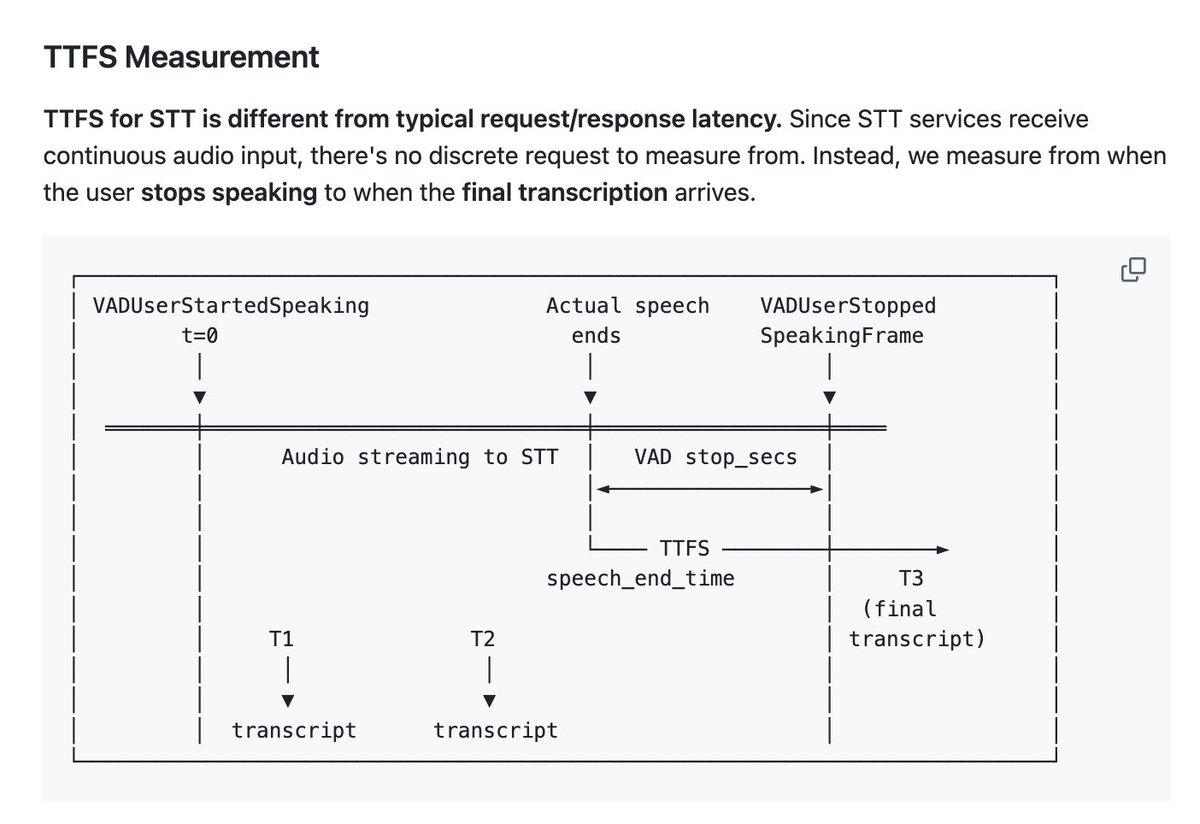
- Median, P95, and P99 "time to final transcript" numbers for hosted STT APIs.
- A standardized "Semantic Word Error Rate" metric that measures transcription accuracy in the context of a voice agent pipeline.
- We worked with all the model providers to optimize the configurations and @pipecat_ai implementations so that the benchmark is as fair and representative as we can possibly make it.
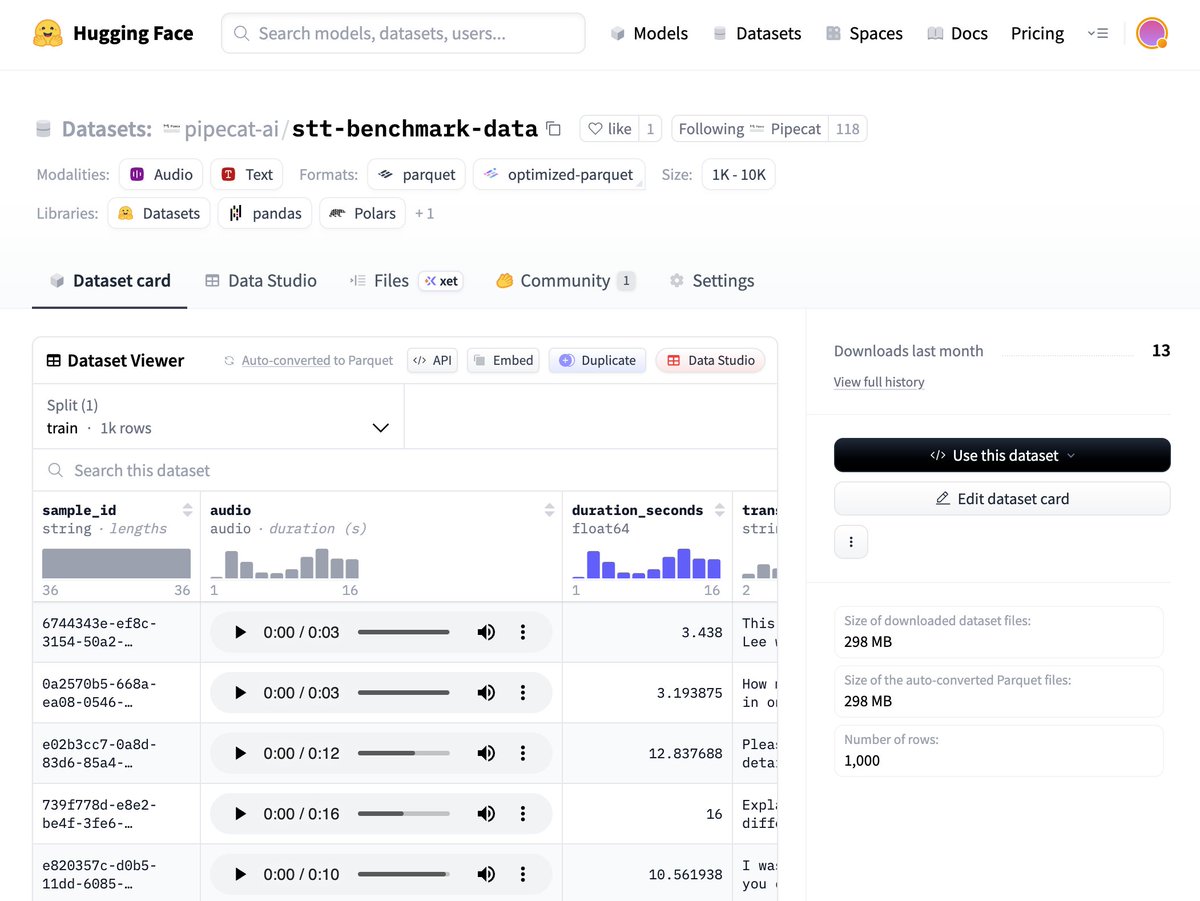
Entirely open source. You can run the benchmark yourself and reproduce the results.