February 13, 2026
Wake up, babe. New Pareto frontier chart just dropped.
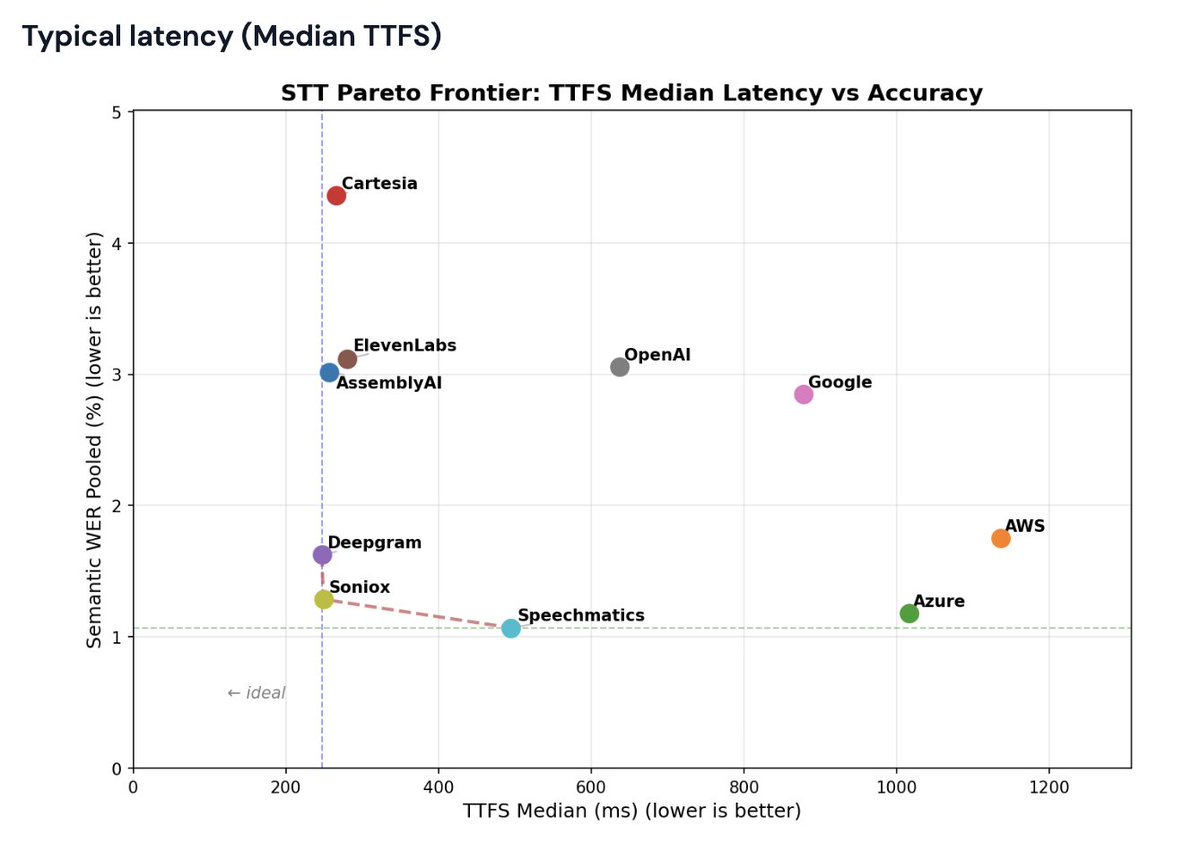
Benchmarking STT for voice agents: we just published one of the internal benchmarks we use to measure latency and real-world performance of transcription models.
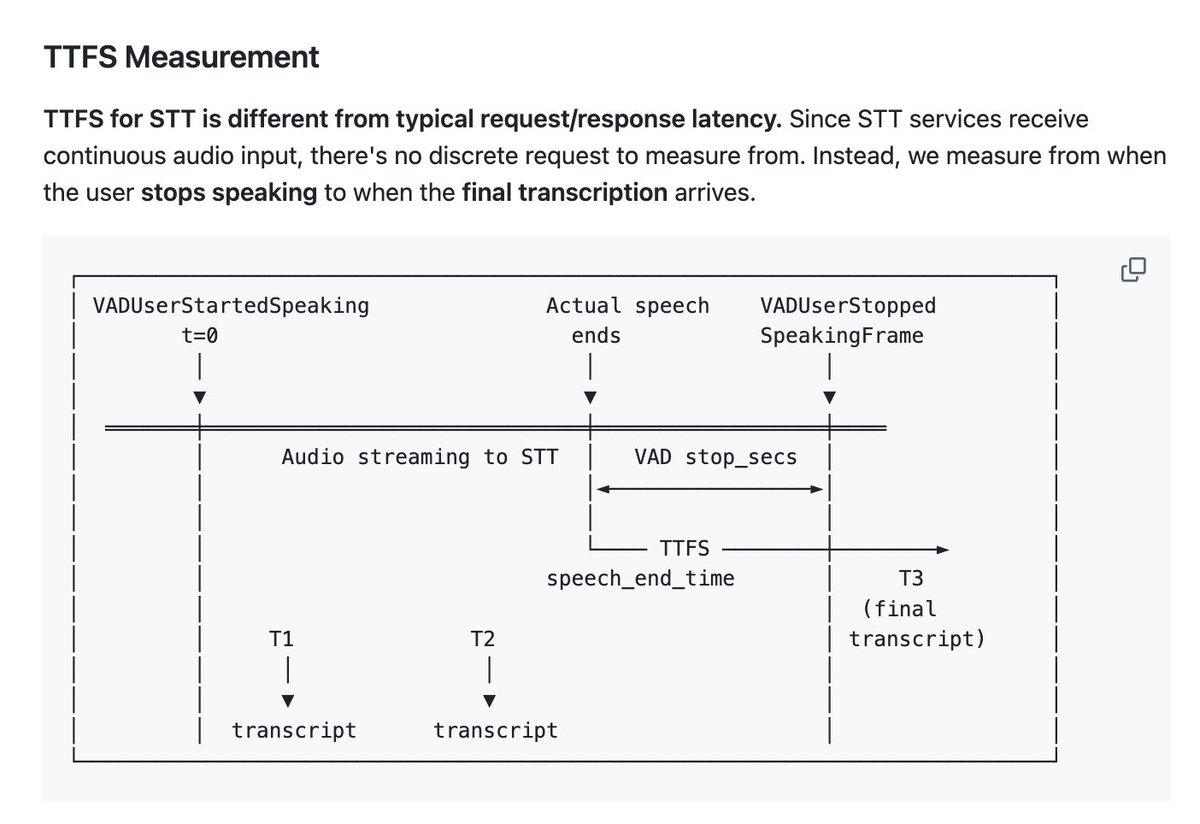
- Median, P95, and P99 "time to final transcript" numbers for hosted STT APIs.
- A standardized "Semantic Word Error Rate" metric that measures transcription accuracy in the context of a voice agent pipeline.
- We worked with all the model providers to optimize the configurations and @pipecat_ai implementations so that the benchmark is as fair and representative as we can possibly make it.
Entirely open source. You can run the benchmark yourself and reproduce the results.

Detailed technical post about this voice agents STT benchmark: https://t.co/9OWZuorx4f
Benchmark source code: https://t.co/KruEBoxRD6
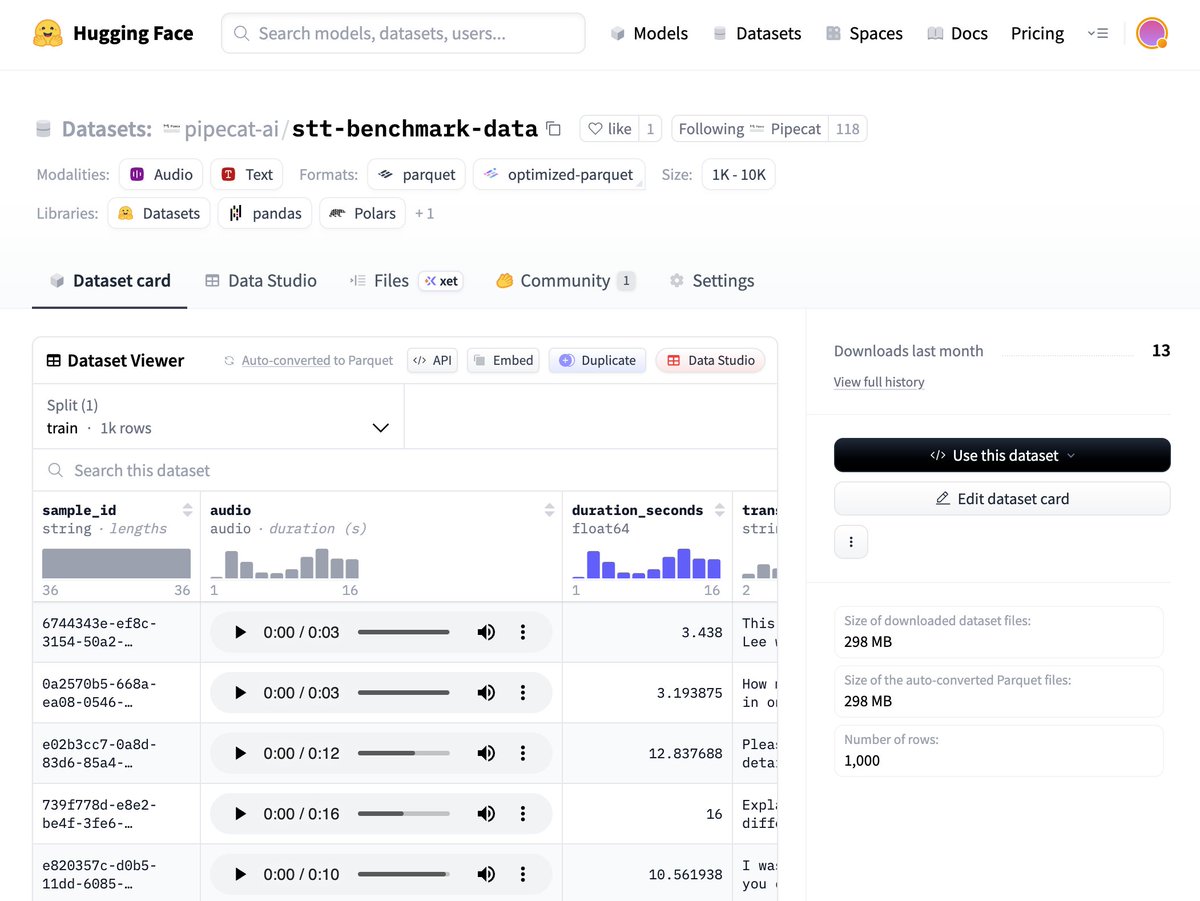
Benchmark data set on @huggingface . 1,000 human speech samples, captured from real voice agent interactions, with verified ground truth transcriptions: https://t.co/qbsny8xquj
@huggingface We also published a benchmark of LLM performance in real-world voice agent use cases recently (long, multi-turn conversations with multiple tool calls and accurate instruction following required).
https://t.co/llf3EkwNFE
Open source voice agent LLM benchmark:
Technical deep dive into voice agent benchmarking: