February 12, 2026
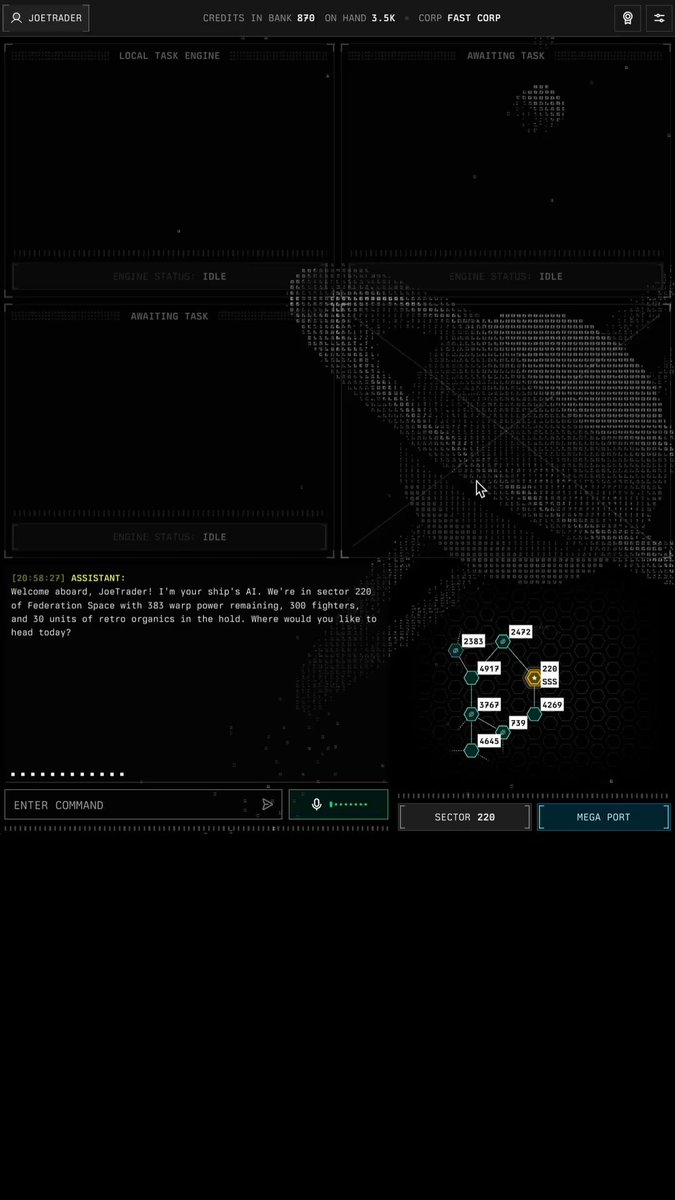
Voice-controlled UI.
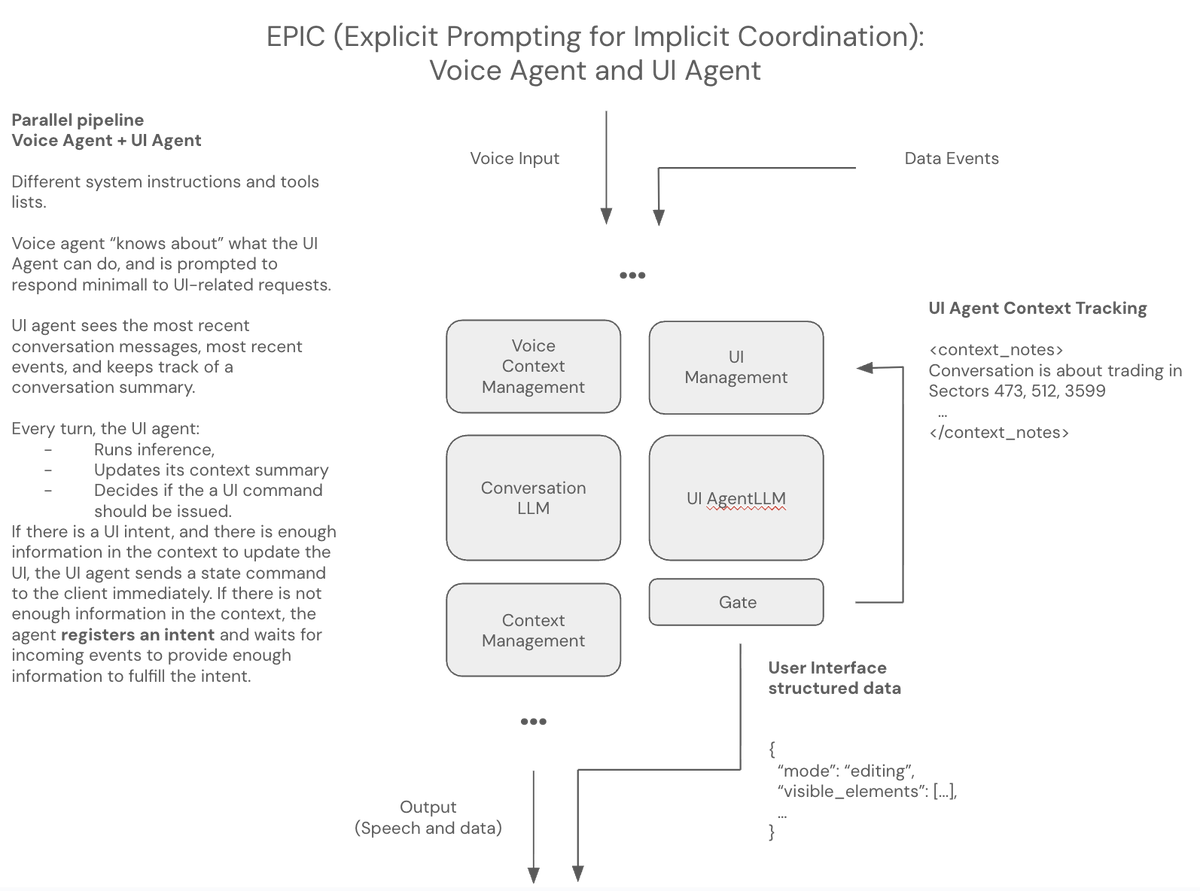
This is an agent design pattern I'm calling EPIC, "explicit prompting for implicit coordination." Feel free to suggest a better name. :-)
In the video, I'm navigating around a map, conversationally, pulling in information dynamically from tool calls and realtime streamed events.
There are two separate agents (inference loops) here: a voice agent and a UI control agent. They know about each other (at the prompt level) but they work independently.
The critical things here are:
- We can't block the voice agent's fast responses.
- The voice agent already has a lot of instructions in its context and a large number of tools to call, so we don't want to give it more to do each inference turn.
So we prompt the voice agent to know, at a high level, what the UI agent will do, but to ignore or respond minimally to UI-related requests. This adds relatively little complexity to the voice agent system instruction.
We prompt the UI agent with a small subset of world knowledge, a few tools, and a lot of examples about how to perform useful UI actions in various contexts.
Each time the user speaks, both agents run inference.
Every turn the UI agent can:
1. Do nothing.
2. Make a tool call that sends a message to the client to update the UI.
3. "Register an intent" to update the UI, and wait for more information.
For example, I might say something like, "Show me on the map the last place we found a really good deal on quantum foam." The UI agent might not know where on the map that is. But it knows that the voice agent will look that information up and the result will appear in the context as a result of that voice agent action. So the UI agent keeps track of the user intent and waits for the information to become available, then updates the UI later, when it has all the necessary parameters to pass to the UI control tool call.
Code is here: https://t.co/CGoZJBpgi7
I'm interested in what other people think of this pattern. There are definitely some pragmatic trade-offs here: limiting the tools and instructions each agent has in its system prompt makes things more fragile.
The agents can get out of sync.
But I've built several versions of UI control using tool calls directly from the voice agent, and I like this pattern better. With direct tool calls, it's very hard to avoid adding unwanted latency to every response that includes a UI update.