February 2, 2026
Benchmarking LLMs for voice agent use cases. New open source repo, along with a deep dive into how we think about measuring LLM performance.
The headline results:
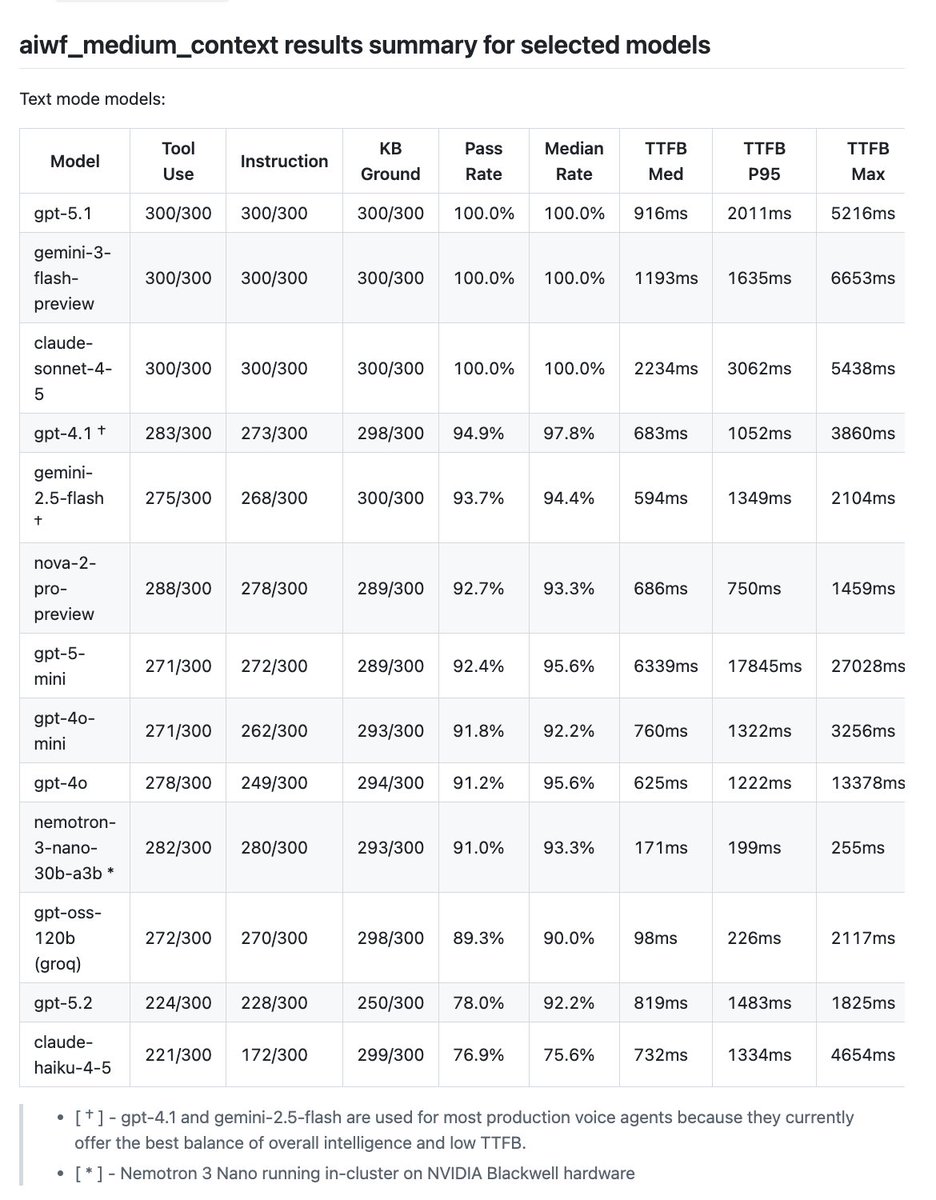
- The newest SOTA models are all *really* good, but too slow for production voice agents. GPT-4.1 and Gemini 2.5 Flash are still the most widely used models in production. The benchmark shows why.
- Ultravox 0.7 shows that it's possible to close the "intelligence gap" between speech-to-speech models and text-mode LLMs. This is a big deal!
- Open weights models are climbing up the capability curve. Nemotron 3 Nano is almost as capable as GPT-4o. (And achieves this with only 30B parameters.) GPT-4o was the most widely used model for voice agents until quite recently, so a small open weights model scoring this well is a strong indication that production use of open weights models will grow this year.
Voice agents are a moderately "out of distribution" use case for all of our SOTA LLMs today. Literally, in the sense that there's not enough long, multi-turn conversation data in the training sets.
Everyone who builds voice agents knows this intuitively, from doing lots of manual testing. (Vibes-based evals!) This benchmark scores LLMs quantitatively on instruction following, tool calling, and knowledge retrieval in long-context, multi-turn conversations.
Blog post[1]
Benchmark code[2]
Side note: we call this the aiwf_medium_context benchmark because it's a descendant of tooling we originally built to test the performance of the pre-release Gemini Live model that powered the…