January 6, 2026
NVIDIA just released a new open source transcription model, Nemotron Speech ASR, designed from the ground up for low-latency use cases like voice agents.
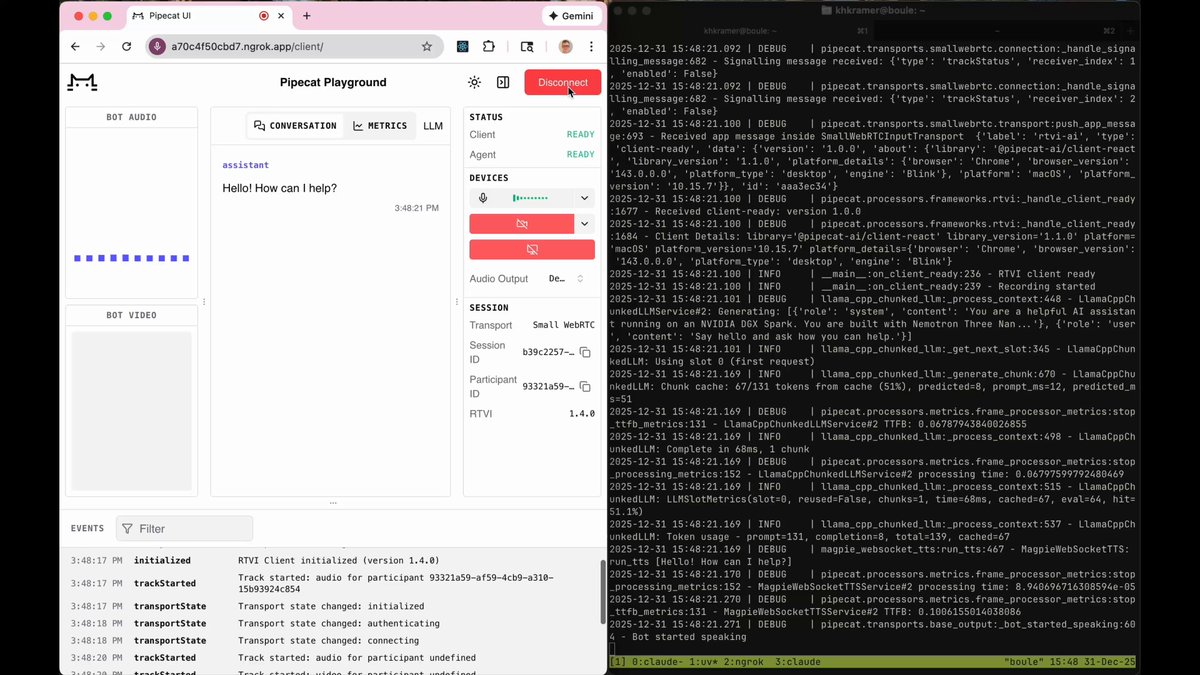
Here's a voice agent built with this new model. 24ms transcription finalization and total voice-to-voice inference time under 500ms.
This agent actually uses *three* NVIDIA open source models:
- Nemotron Speech ASR
- Nemotron 3 Nano 30GB in a 4-bit quant (released in December)
- A preview checkpoint of the upcoming Magpie text-to-speech model
These models are all truly open source: weights, training data, training code, and inference code. This is a big deal! Jensen said in the CES keynote yesterday that he expects open source models to catch up to proprietary models this year in a number of categories. NVIDIA is putting their weight behind making this happen. (As Alan Kay said, the best way to predict the future is to invent it.)
The code for this agent is open source too, of course. You can deploy it to production with @modal and @pipecat_ai cloud, or run locally on an @nvidia DGX Spark or RTX 5090.
Here's a technical write-up about the voice agent in the video above, the three NVIDIA models, how to deploy to production, and some fun optimizations if you're running locally on a single GPU:
Code is all here[2]
You can deploy these models to @modal cloud really easily. (I love the Modal developer experience.)
To run locally, you'll need to build a Docker container (because, you know, bleeding edge vLLM, llama.cpp, CUDA for Blackwell, etc). But…