December 17, 2025
Today is Gemini 3 Flash launch day! I've been experimenting with pre-release checkpoints of this model and it's very good. I've been using it for various personal voice agent stuff, long-running text-mode agent processes, and of course running benchmarks.
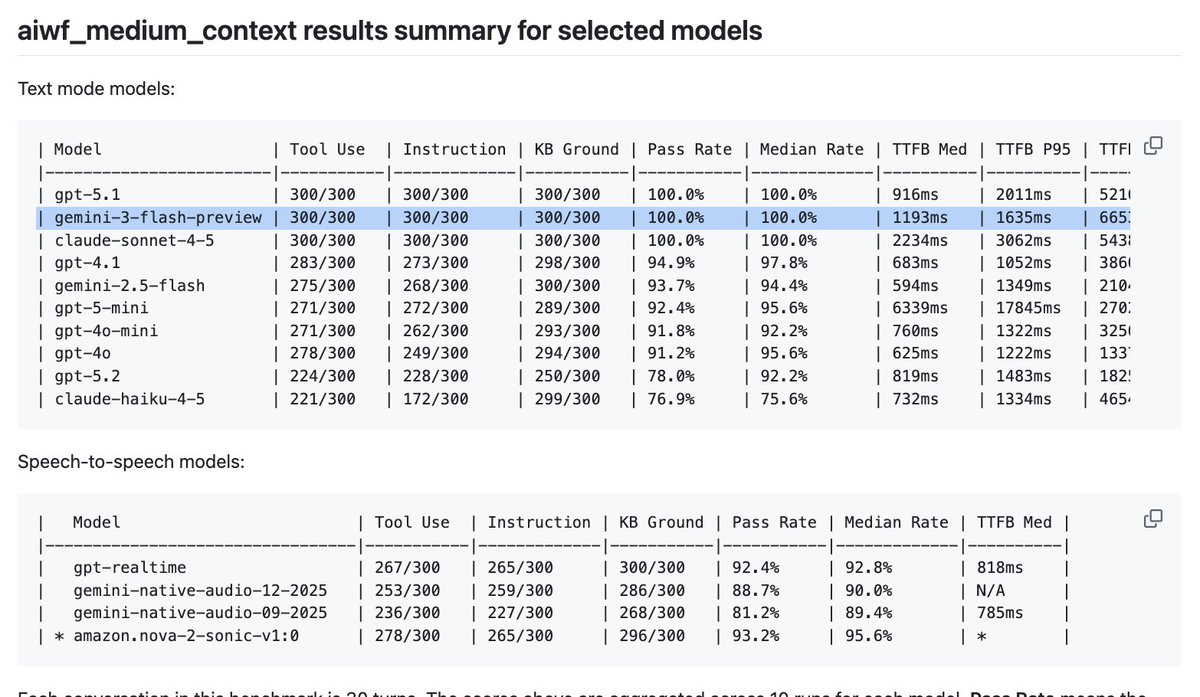
Gemini 3 Flash saturates my relatively hard multi-turn bechmarks, even with thinking set to the "MINIMAL" level. And, as with Gemini offerings in general, cost per token is quite a bit lower than other similarly capable models.
The main question for voice AI developers is whether this model will have the same really, really good TTFT numbers that gemini-2.5-flash does, once Google has completely ramped up their provisioning of TPUs for it.
Right now we're seeing a median TTFT of ~1s. That's too slow for most voice agent use cases. But given that Gemini 2.5 Flash TTFTs are in the 500-600ms range, I'm optimistic! It's also possible to contract with Google Cloud for dedicated inference compute, which is an option for optimizing TTFT if you're running voice agents at scale.
There's a new @pipecat_ai release today, with support for Gemini 3 Flash. The 3 Flash model has the same new thought signature behavior as the Gemini 3 Pro model. You need to maintain the thought signatures from the model as part of the conversation context, even with thinking mode set to "MINIMAL".
You can talk to Gemini 3 Flash for free at pipecat .ai.