November 15, 2025
This post about customizing models and optimizing inference for voice agents, from the team at @modal, is really cool.
Almost every enterprise I talk to about voice agents wants to be able to use their internal data to iteratively improve the performance of their AI agents.
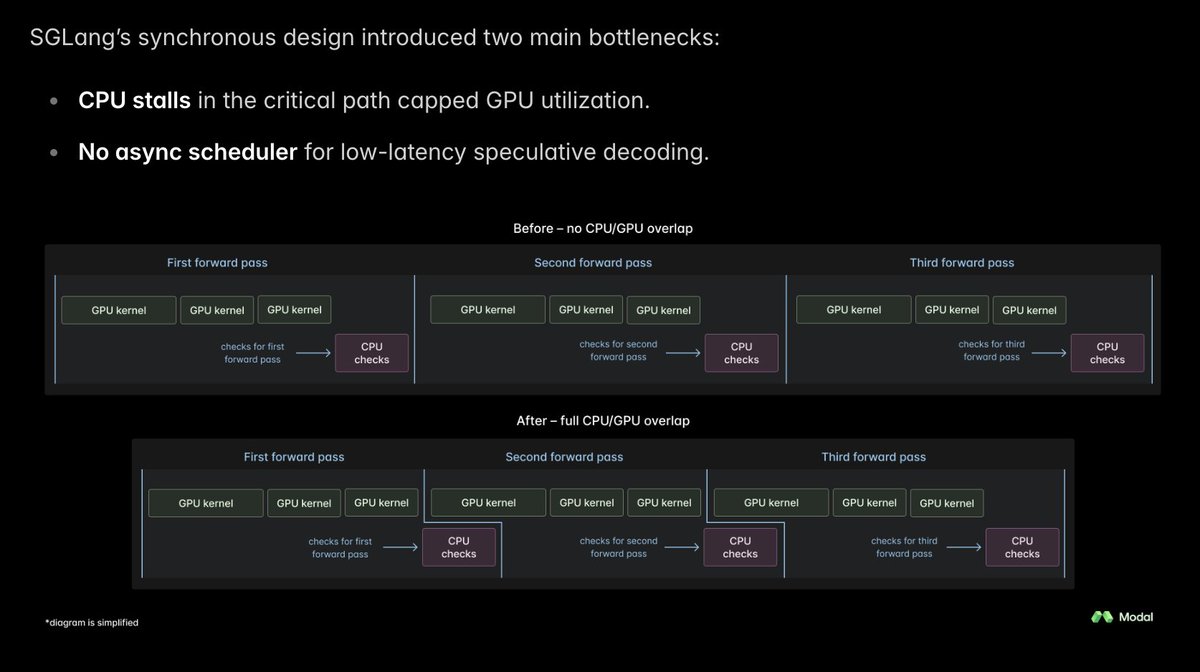
The Modal team worked with Decagon to build model training tooling and data sets, train a custom speculative draft model, and modify the SGLang inference stack to serve the LLMs used by Decagon optimally on H200 GPUs.
The blog post says that they've achieved a P90 latency of 342ms with this combined work. That's really good! Based on the context in the blog post and the flow diagram, I'm assuming this is the TTFT for the LLM inference part of the voice agent pipeline. So an apples-to-apples comparison with using a frontier lab model would be roughly:
342ms + ~10ms for local networking between the agent code and the SGLang server
vs
~600ms for Gemini 2.5 Flash or ~900ms for GPT-5.1
Also note that the P90 varies much more day-to-day for the foundation lab models used via an API than for the dedicated infrastructure approach that the Modal blog post describes.

The post is here[1]