November 8, 2025
At the voice agent meetup next week, the theme is new patterns for agents. We are increasingly building voice agents that are much more than a single LLM prompt running in a loop.
State machines, various kinds of multi-agent systems, combining "fast" and "thinking" models, guardrails processes, memory sub-systems, ...
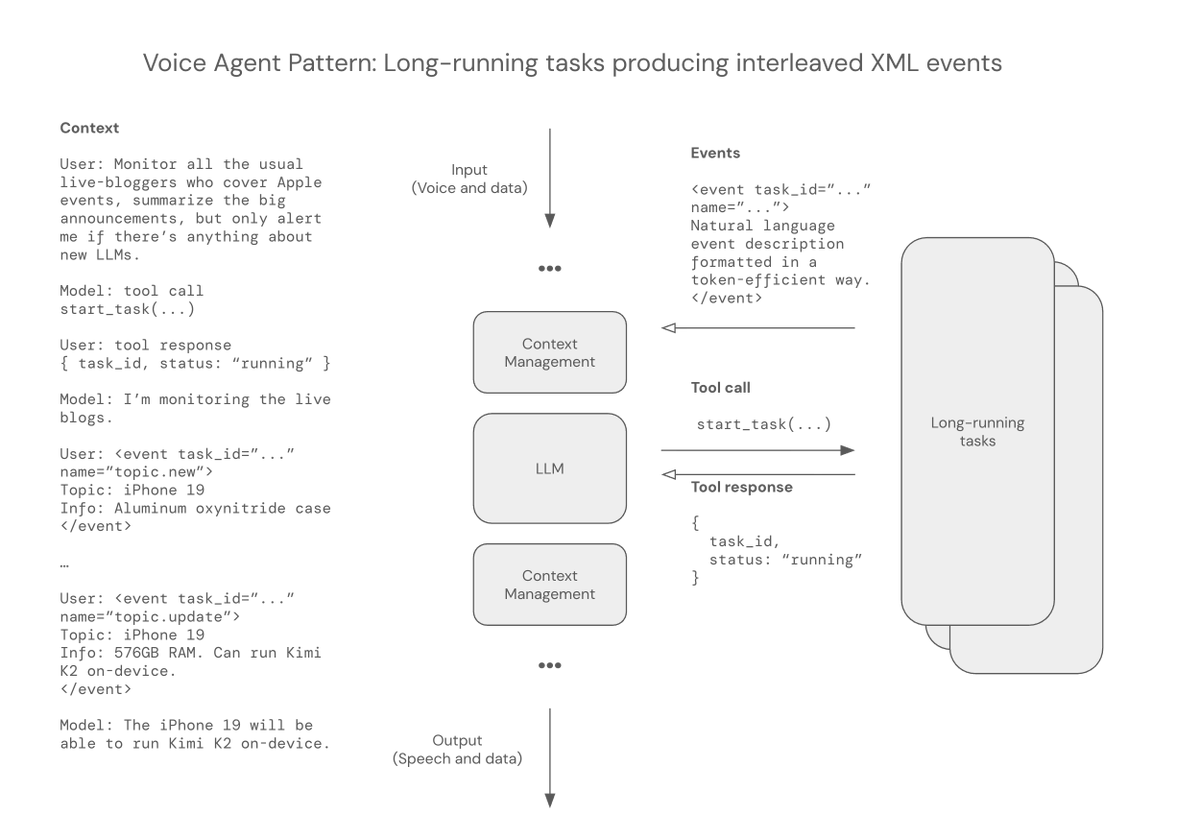
I'm starting to document some these new patterns. Here's one that I particularly like: using a tool call to start a long-running task, returning from that tool call immediately with a very simple success/failure response, then injecting events into the voice agent context for as long as the task needs to run.
Some notes about this:
- Interleaving user speech input and events metadata works well with most LLMs. More capable LLMs handle this better, as you would expect. You can format the events a lot of different ways, but wrapping natural language in XML tags is my preferred approach, at least for now. Even if the events are "naturally" JSON, we often create functions to turn the JSON into plain text. (We should build benchmarks to test how much this actually helps maintain instruction following accuracy!)
- You'll want to prompt the LLM to understand the event structures and ideally provide few-shot examples of what the events mean. But a big, SOTA LLM can do a surprising amount of just figuring stuff out, with this approach.
- The context manager or event insertion handler can decide whether to trigger inference or not, based on the type of event, how long it's been since receiving an event, etc.
- Generally, whenever the user speaks, you trigger inference. At which point the LLM has all the event context, plus the user speech, as context.
- Mixing user speech input with structured data in multi-turn conversations definitely makes hallucinations more common. This seems slightly worse if the structured data is inserted the way we're doing here, compared to using tool response messages. Which probably makes sense, from a training data distribution perspective. But you can't use tool response messages for long-running tasks. (We've tried. For example, by synthesizing tool calls the LLM didn't make, so you have lots of call/response pairs. And putting in response messages that don't have a matching tool call immediatedly prior. These things take the models way out of distribution. Don't do them!)
Come hang out with us on Wednesday next week in person in SF or via livestream, if you're building realtime, multimodal AI and want to talk to other people who are shipping to production, experimenting, and building tooling.

RSVP here[1]