September 10, 2025
Re talking past each other:
Some people are mostly thinking about the "CPU" in karpathy's LLM operating system (loosely speaking), and some people are mostly thinking about tools and libraries (loosely speaking).
> in ai products, quality dominates a lot, esp for generally intelligent products, everything else like privacy cost etc is just rounding error
I agree with this, and it pushes in the direction of both using the biggest, best (probably proprietary models, for the foreseeable future) *and* using small models everywhere all the time.
Application responsiveness is an important part of overall quality. I'm the guy you pay to reduce your network latency to the absolute minimum. I can help you get P50 cloud inference time down to ~20ms or so, absolute best case scenario. 20ms is an eternity of clock cycles. 20ms is a time interval that is perceptible to a human user.
Language models are so useful that we're going to use them more and more, everywhere in our code. Some of that inference is going to need to happen much faster than you'll be able to do it in the cloud.
My mental model for imagining this near-future world where we use language models everywhere, all the time, in our code is: why would you write a regular expression when you have an LLM in your toolkit?
General intelligence is so valuable that we're going to be using LLMs in the cloud, all the time in all our software. And specific intelligence that's shaped like LLM inference is also so valuable that we're going to be using local models all the time, too.
in a normal world i'd make this a blogpost but i'm quite busy with tmr's ✨big announcement✨
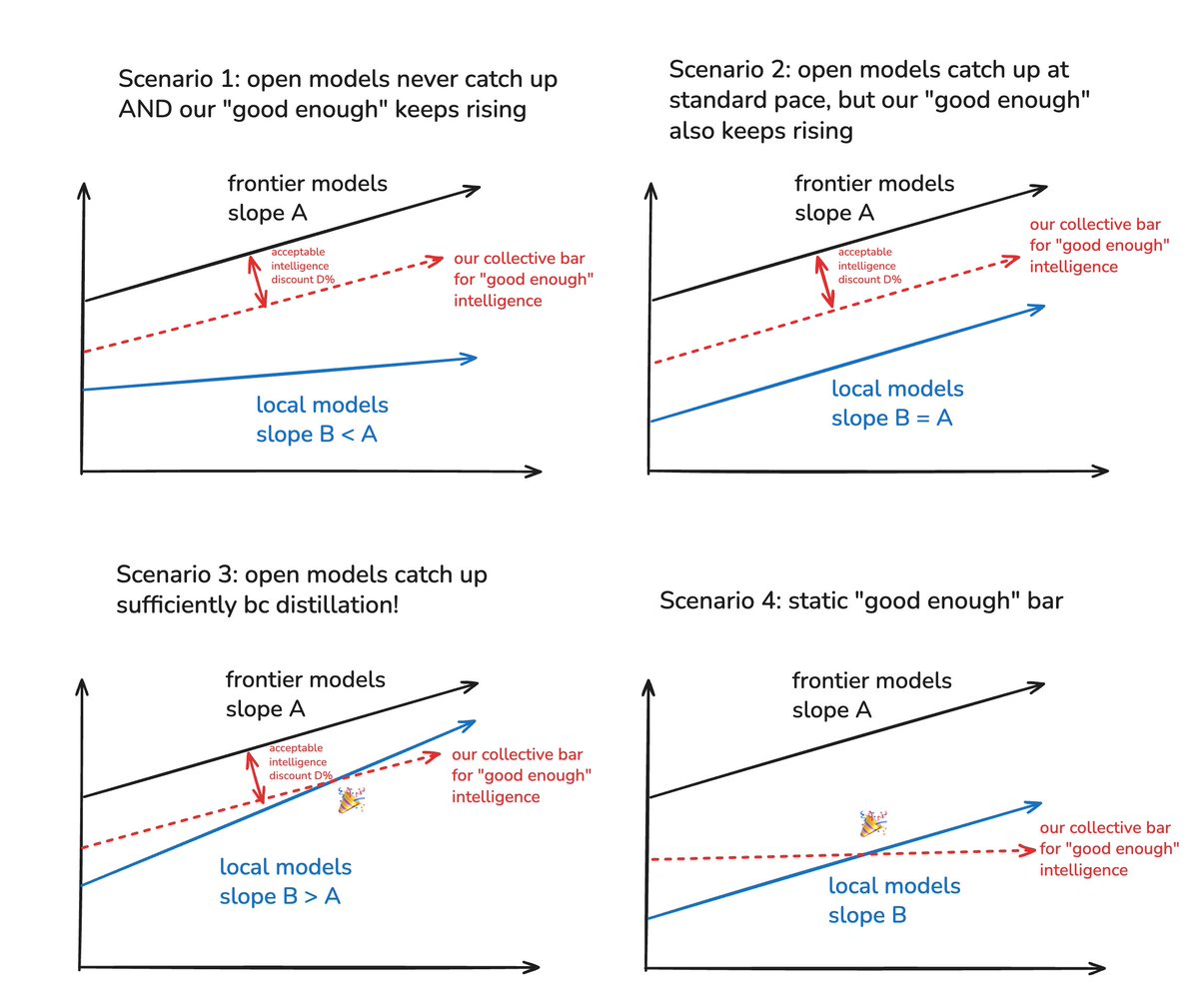
so basically here are the 4 valid scenarios in the local models dream
most big lab people believe 1, most investors/biz people believe 2, huggingface et al believe either 3 or 4, and