July 27, 2025
Local voice AI with a 235 billion parameter LLM. ✅
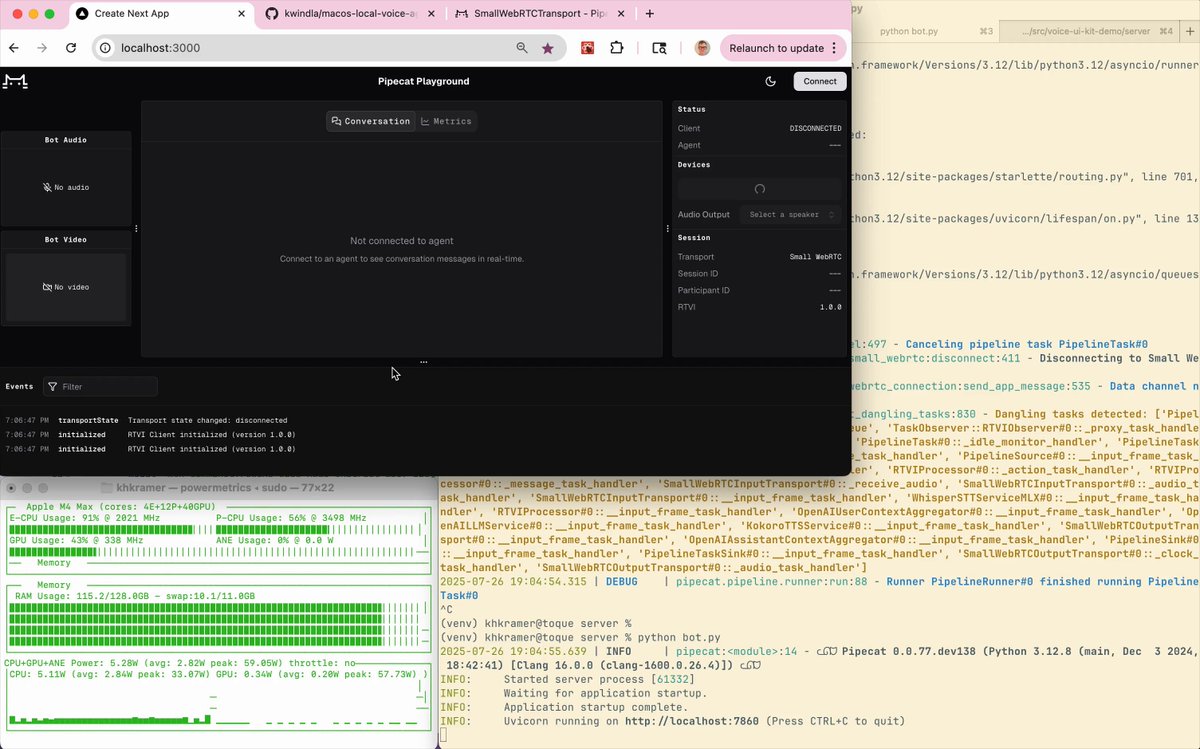
- smart-turn v2
- MLX Whisper (large-v3-turbo-q4)
- Qwen3-235B-A22B-Instruct-2507-3bit-DWQ
- Kokoro
All models running local on an M4 mac. Max RAM usage ~110GB.
Voice-to-voice latency is ~950ms. There are a couple of relatively easy ways to carve another ~100ms off that number. But it's not a bad start!
Code is here:
This was made possible by the quant @ivanfioravanti posted today and his advice about changing the memory limits for this big model.
And @Prince_Canuma's work on mlx-audio made implementing…