July 18, 2025
Smart Turn v2: open source, native audio turn detection in 14 languages.
New checkpoint of the open source, open data, open training code, semantic VAD model on @huggingface, @FAL, and @pipecat_ai.
- 3x faster inference (12ms on an L40)
- 14 languages (13 more than v1, which was english-only)
- New synthetic data set `chirp_3_all` with ~163k audio samples
- 99% accuracy on held out `human_5_all` test data
Good turn detection is critical for voice agents. This model "understands" both semantic and audio patterns, and mitigates the voice AI trade-off between unwanted turn latency vs the agent interrupting people before they are finished speaking.
Training scripts for both @modal_labs and local training are in the repo. We want to make it as easy as possible to contribute to or customize this model!
Here's a demo running the smart-turn model with default settings, aimed at generally hitting 400ms total turn detection time. You can tune things to be faster, too.
You can help by contributing data, doing architecture expermints, or cleaning open source data! Keep reading ...
This model is designed to be used together with a traditional VAD model for voice AI conversations.
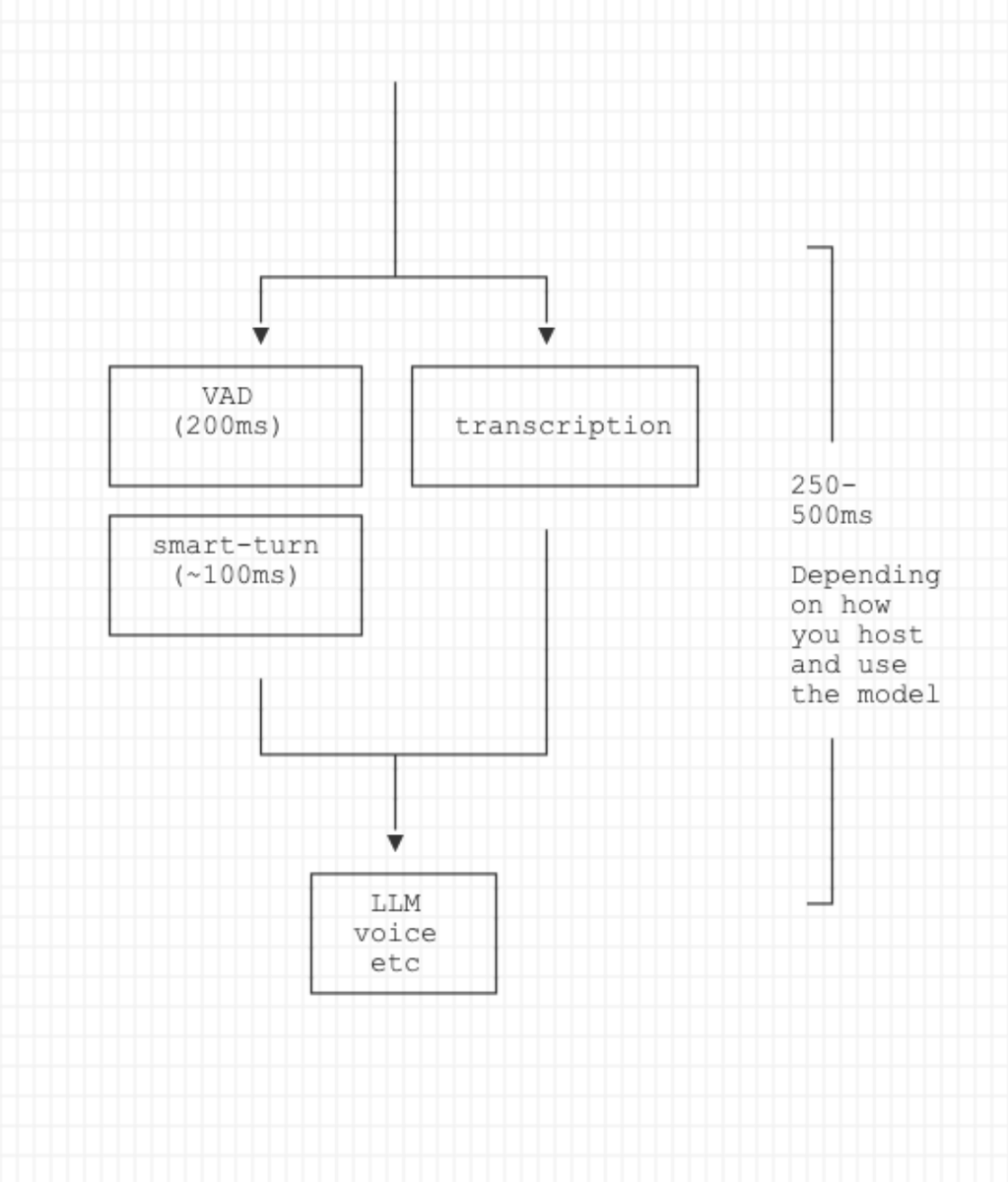
The voice AI pipeline typically looks like this:
1. A very short VAD timeout chunks the audio stream for the smart-turn model
2. Transcription runs in parallel
3. Transcription output is gated on turn detection before going to the rest of the pipeline
The basic idea here is that you want turn detection to happen faster than transcription. It doesn't really matter how much faster, because you need "final" transcription fragments before you can run LLM inference. We're generally aiming for ~400ms end-to-end for turn detection.
But other approaches are possible.
For example, you can build pipelines that do greedy LLM inference on every transcription segment, and gate *that* output. This gets youe even lower latency, but cost is higher because you're throwing away all the LLM inference for every incomplete turn speech segment.
Or, doubling down on the greedy inference approach, you can skip transcription entirely and feed every speech segment to a model capable of native audio inference. Again, throw away that output for speech segments that the smart turn model classifies as incomplete.
Blog post with code examples and docs pointers:
- https://t.co/YeAHFcUCbO
Repo with training code and development notes:
- https://t.co/YbiYc7Y8VT
Weights:
- https://t.co/eiGkCLJlOs
Data sets:
- https://t.co/CKxE7QPNzo
Use the model for free in Pipecat Cloud + @FAL:
- https://t.co/byICYT9Rv6
Here's a demo app hosted on @ vercel and Pipecat Cloud:
- https://t.co/FdX85PzUdm
- https://t.co/gVRw4Bxwuk