June 21, 2025
The @OpenAI gpt-4o-mini-tts model is very good and a lot of fun to experiment with.
It's also different from the other TTS models we typically use for realtime voice AI applications. The model is steerable: you can tell it how to say things in addition to telling it what to say.
Here's an interactive story with two voices, each generated by a different configuration of gpt-4o-mini-tts.
Here's the demo code:
This code is a nice example of custom frame processors in Pipecat. More on that below. But first let's talk about steerability.
You can provide gpt-4o-mini-tts `instructions` for how the voice should talk.
The narrator voice…
Steerability is a natural next step in TTS model evolution. In this regard, using gpt-4o-mini-tts feels like an early look at the next generation of TTS models.
It's worth noting, though, that steerability is not always useful. For many voice agent use cases, predictability is much more important than "dynamic range." Think of this as similar to adjusting the temperature parameter of LLM inference. Sometimes you want variation. Sometimes you don't!
Perhaps relatedly, this steerable TTS model seems a little more prone to audio hallucinations than other SOTA TTS models. I wouldn't hesitate to use it in production. But there are strings of text you can feed it that will often produce disfluencies or unexpected speech.
To be fair, that's true of all TTS models. And it's very hard to benchmark this. So it's possible that I'm wrong about relative rates of disfluency and hallucination. (If it were easy to benchmark long-tail voice generation issues, the very capable people who train these models would already have eliminated all the edge cases!)
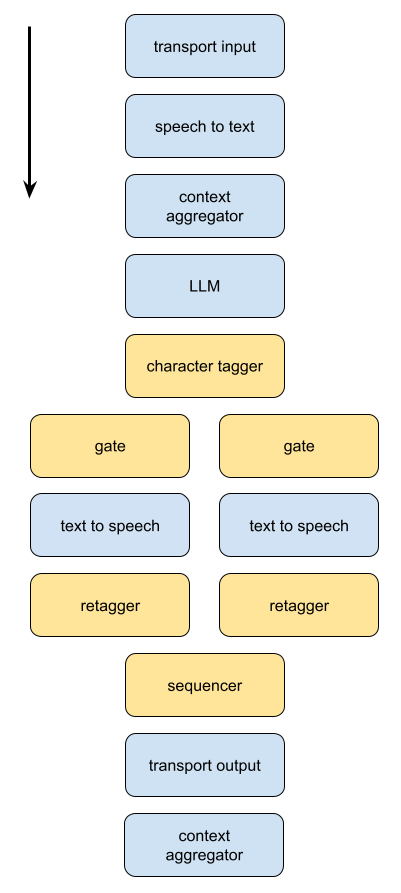
The demo code here is a nice example of a fairly common pattern for custom frame processors in Pipecat.
We're prompting an LLM to narrate a story with two voices - a narrator, and a main character.
We ask the LLM to format its output like this:
----
Narrator
Rosamund work up early because it was Saturday. She thought to herself
Rosamund
I hope that the friendly owl comes back to visit today.
----
Then in the Pipecat pipeline, we divide each response into subsections:
1. Stripping out the "voice tag"
2. Directing each section to either the narrator or character TTS
3. Re-inserting the voice tag
4. Preserving the sequence of the sections, so everything plays in the right order.