May 1, 2025
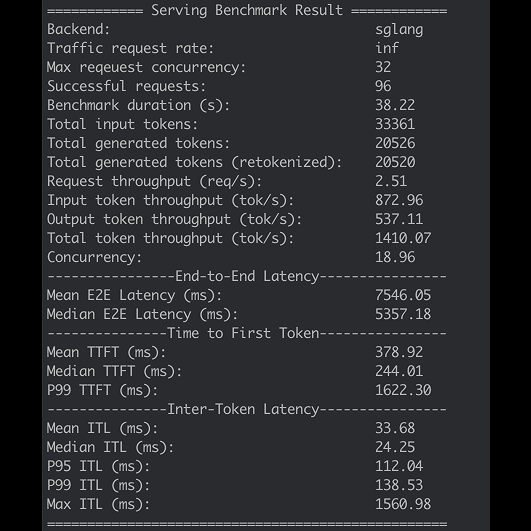
Nice thread from @baseten with metrics and technical details about serving Qwen3 235B with SGLang.
244ms is a *very* good P50 TTFT for such a big model.
Note that this number is the server-side metric. For end-to-end TTFT you'll also need to factor in the network stack processing and transit time. So add ~10-100ms depending on how far away from the cluster your clients are.
For conversational voice AI use cases, I'd like to see a smaller spread between P50 and P95. I'm 100% sure that's achievable here with different concurrency/batching tuning.
Early benchmarks of Qwen 3 with SGLang show promising initial results and key avenues for improvement.
We're seeing:
- Up to 76 TPS per user for real-time
- Up to 4600 total token throughput for batch
- 32 concurrent requests as a good balance for prod
Details in 🧵