March 20, 2025
Lots of new stuff in the @pipecat_ai 0.0.59 release today. (26 items in just the "Added" section of the changelog.)
The highlight for me is support for OpenAI's new speech-to-text and text-to-speech models, plus the new capabilities of the Realtime API.
If you're building voice AI agents, OpenAI shipped a lot of things that are really useful today. 🧵 ...
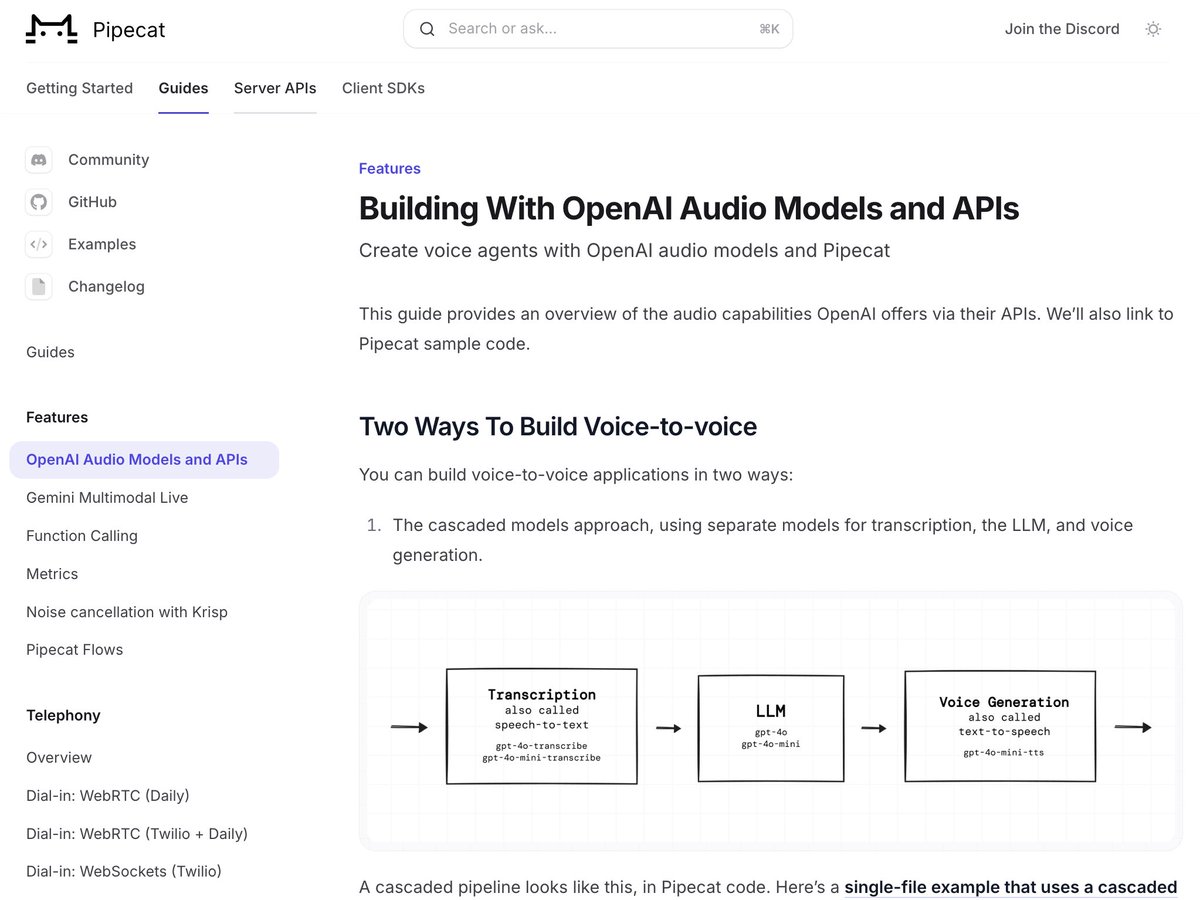
Two new transcription (stt) models: gpt-4o-transcribe and gpt-4o-mini-transcribe.
What most excited me about these models is that:
1⃣ They are being trained with realtime use cases in mind, and
2⃣They are fully promptable. They do more than just "transcription." I've been experimenting with using audio-native LLMs to do transcription, and there's a lot of new territory to explore, here.
A new voice (tts) model: gpt-4o-mini-tts. Again, promptable!
Experiment interactively with gpt-4o-mini-tts voices and prompting here: https://t.co/wSvLnsHdLC
Four significant new Realtime API features:
➡️ Noise reduction
➡️ Semantic VAD (turn detection)
➡️ context.item.retrieve (very helpful for context management)
➡️ Support for gpt-4o-mini-transcribe for transcribing user audio input
All of these are aimed at solving real pain points for production voice AI agents. I'm particularly interested in improved turn detection. Here's @pbbakkum discussing the new semantic VAD.
https://t.co/Wz98EQZkg3
Here's OpenAI's live stream:
https://t.co/AGmht5UrNJ
I joined the @altryne and the @thursdai_pod crew to talk about how all these new models and features help voice AI developers:
https://t.co/po4fABsSqW
Here's the @pipecat_ai guide to building voice agents that leverage OpenAI audio models and APIs:
https://t.co/RbJA7dmPId
And here's the full 0.0.59 changelog:
https://t.co/FTSMh8nVN7