
January 13, 2025
Open Source, Graphical Voice AI Agent Builder
Create voice agents for complex workflows with Gemini 2.0 and Pipecat.
Technical details in the 🧵
Link to the Pipecat Flows repo:
https://t.co/tRtSVtyrtr
The big challenges with complex voice AI workflows are:
1. Instruction following — does the LLM "remember" and correctly follow the instructions in your prompt, even as the context window gets longer during a multi-turn conversation?
2. Function calling — almost all voice agent workflows depend heavily on function calling. Does the LLM call the functions you define, when needed, with the correct arguments. Can the LLM call multiple functions at a time to perform complex operations?
3. Context awareness — can the LLM pull relevant information out of the context as the context length and the complexity of information in the context window grows? Imagine the metaphorical "needle in the haystack." Can the LLM find the needle when it needs to!
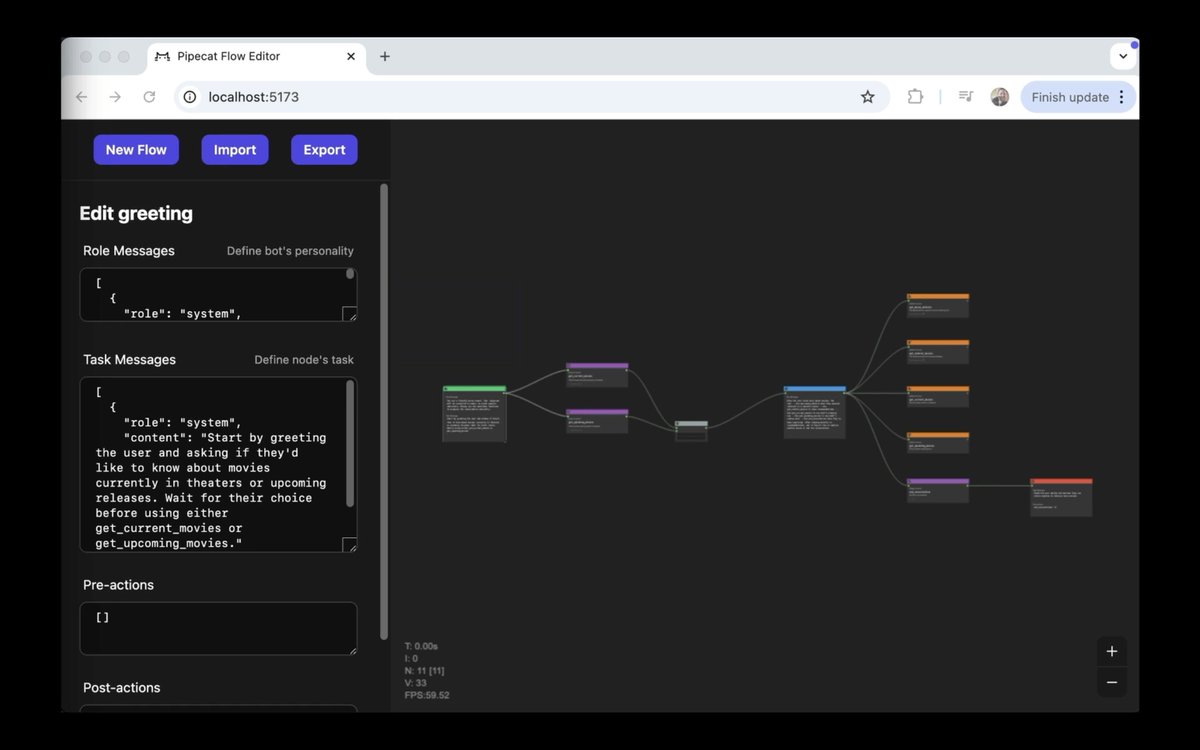
Pipecat Flows is a new architecture that represents a complex agent workflow as a state machine.
Each state is:
- LLM context
- functions for the LLM to call
- next state transition definitions
Moving from one state to the next, you will typically replace or summarize the context. You also usually update the function definitions.
The traditional approach to voice agent workflows is to write a very detailed system prompt for the LLM. The state machine approach is much more reliable for most real-world voice AI workflows.
The Pipecat Flows graphical editor makes creating and updating this kind of state machine as easy as dragging blocks around on a canvas!
tldr — Don't write a system prompt. Draw a state machine.
The Pipecat Flows project is part of the open source, vendor neutral, @pipecat_ai ecosystem.
h/t to @chadbailey59 for the video.
This is the 12th post in our beginning-of-the-New-Year series: 25 multimodal demos and examples for 2025 — building with Gemini 2.0 and Pipecat.