December 22, 2024
Better/faster/cheaper voice AI turn detection with Gemini 2.0
The code that determines when the agent should respond to the user is some of the most important code in your voice AI agent.
The technical terms for this job are "turn detection" or "phrase endpointing."
If the voice AI responds before the user has finished their thought, the conversation is choppy and unproductive. If the AI waits too long, the conversation is slow and frustrating.
There are a number of ways to approach this. You can:
1. Use a fast "voice activity detection" model to detect pauses in speech. Respond when the user pauses.
2. Use a specialized phrase endpointing model that operates on transcribed text, pattern-matching on text semantics.
3. Train a specialized phrase endpointing model that operates directly on audio.
4. Leverage the native audio capabilities of a SOTA LLM like Gemini 2.0.
We've benchmarked all four of these, and Gemini 2.0 currently beats other approaches.
Using Gemini is also cheaper than transcribing the audio separately using a transcription service or model.
Here's a short video showing Gemini phrase endpointing in two scenarios. First, correctly handling pauses in natural conversation. Second, requesting a phone number (which is a common activity in a use case like customer support).
You can see the Completeness check lines in the terminal output, printed each time Gemini processes a chunk of audio.
The demo code from the video is here:
https://t.co/Y8aL9zAhQb
Phrase endpointing is an engineering problem, so there are trade-offs and the right solution will vary depending on the use case.
Today, most voice AI agents use only voice activity detection — (1) in the list above.
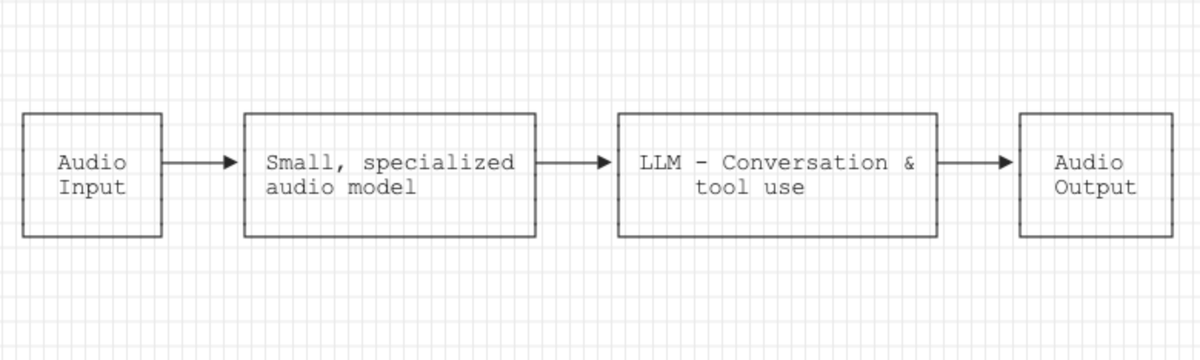
My prediction for 2025 is that we will generally move to (3) and (4) — native audio endpointing using either small, specialized models or leveraging SOTA LLMs.
The advantage of specialized models is that they are small enough and fast enough to run in-line as part of the audio processing pipeline.
The phrase endpointing model controls an audio buffer. When the model predicts that the user is finished speaking, the buffer is sent to the LLM for inference.
A model like this replaces the VAD model in today's typical voice agent pipeline.
The advantages of using a full-sized LLM like Gemini are:
➕ Flexibility. Gemini is good at a wide range of tasks. It operates in 38 languages and can switch between languages seamlessly. You can prompt Gemini to understand speech patterns for specific tasks. (The phone number input rules in the demo video above are "just part of the prompt.")
➕ Iteration speed. Testing a prompt change is much faster than fine-tuning a model.
➕ Cost. Gemini 2.0 Flash pricing hasn't been announced yet. The model is still an experimental preview. But using Gemini 1.5 Flash pricing as a benchmark, Gemini is actually cheaper than using a traditional transcription API or model. This is true even though we are making three greedy inference calls to Gemini for every candidate audio chunk. (!!) I had to do this math several times to convince myself I wasn't making a mistake.
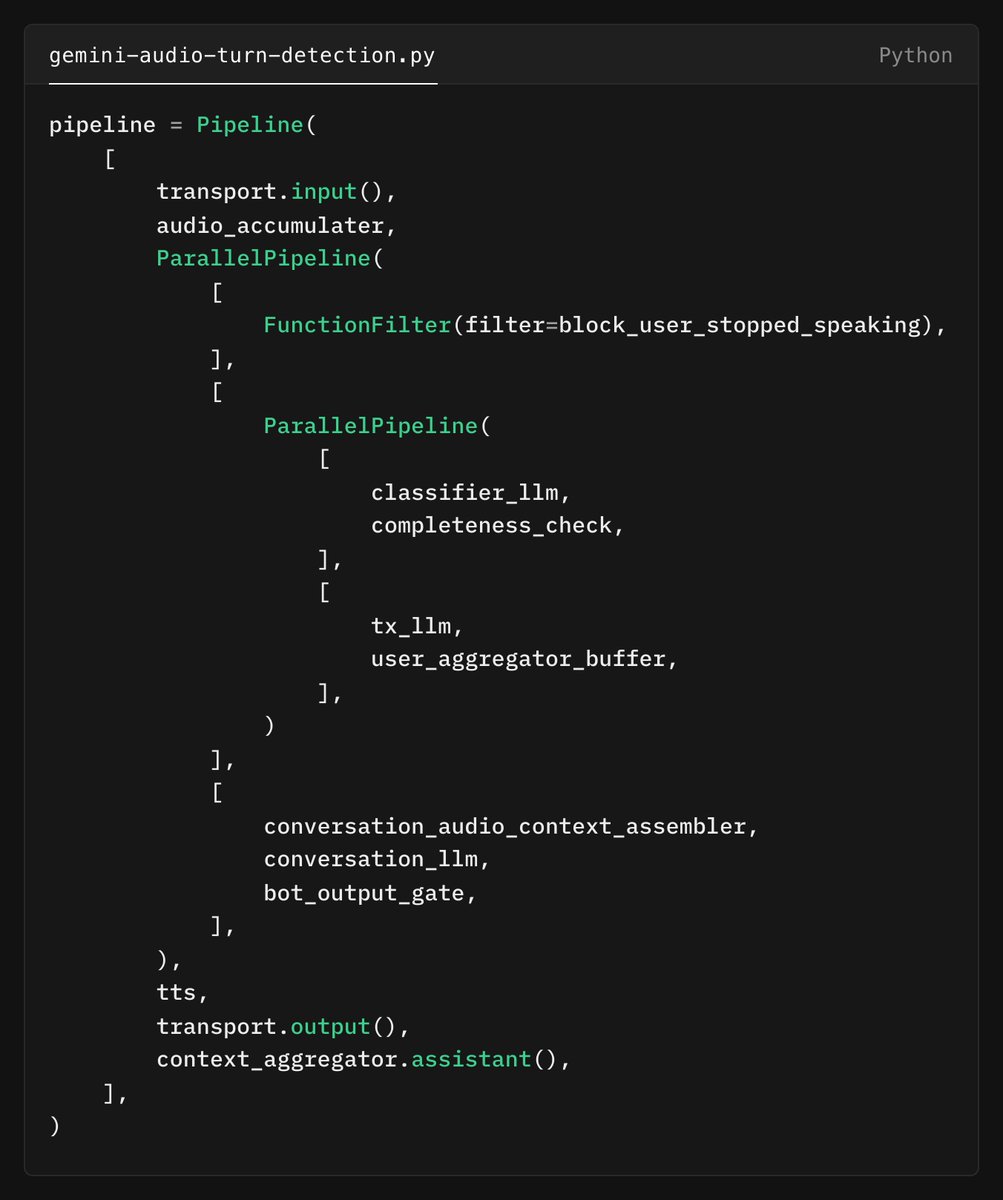
Did you catch that about calling Gemini three times for each audio chunk? Here's the algorithm
1. A VAD model (set to use a short pause interval) segments the input audio into chunks.
2. As soon as the VAD fires, we make three parallel calls to Gemini: for phrase endpointing, to transcribe the audio, and to perform the normal conversation inference.
3. We gate the conversation output until we get an answer back from the endpointing call. If Gemini determines that the user is finished speaking, we open the gate and send output to the user. If Gemini says nope, we throw the transcription and LLM output away.
4. We use only the user's most recent input audio in each conversation inference request. Sending audio to Gemini is really nice, because Gemini can process all of the nuances of the user's speech. But audio uses a lot of tokens. Sending a lot of tokens to the LLM increases both cost and latency. So after we use the audio once, we replace it with the transcription for subsequent conversation turns.
Again, these three calls to Gemini are actually cheaper than using a traditional API or model for transcription. And Gemini's transcription benchmarks are very good — easily on par with dedicated transcription models.
This pipeline is also fast, because we're doing all of the inference in parallel. The classifier outputs a single token, so it almost always finishes about the same time that the conversation inference delivers its first response chunk.
There's some complexity here. I used nested parallel pipelines to implement this as a @pipecat_ai example.
This works so well, though, that I think the complexity trade-off is worth it for many use cases.
I expect that one or more Pipecat contributors will wrap this demo logic into a nicely encapsulated processor by the time Gemini 2.0 is GA.
This is part 5 of our series ending/beginning the year: 25 demos for 2025.
We're building lots of fun multimodal, conversational AI examples with @pipecat_ai and @googledevs Gemini. Check back most days for more demos.
Thank you to @cartesia_ai for the voice in the demo video.
Credit to @mark_backman for doing the heavy lifting on the phrase endpointing classification prompt.