December 5, 2024
The voice-to-voice AI Pareto frontier. (You'll never believe this one weird trick ...)
If you're building conversational voice AI apps, you care a lot about:
➟ Latency
➟ Cost
➟ LLM response quality (predictable behavior, coverage of the full surface area of your needs, reliable function calling, "reasoning")
➟ Voice quality (correct pronunciations, consistent tone, appropriate affect, steerability, "human-ness")
AI model performance is a jagged frontier and has been moving fast for all of 2024. This is especially true for conversational voice, because you're usually using several models in combination.
LLMs with native audio capabilities are the newest evolution pushing the performance frontier.
Here's a multi-lingual voice conversation using Gemini Flash 1.5's native audio input.
But there's a problem ...
... well, two problems. Using native audio input for conversational voice has a couple of drawbacks:
➟ Cost (audio uses a lot of tokes)
➟ Latency (basically the same problem - audio is big compared to text so processing audio is slower than processing text)
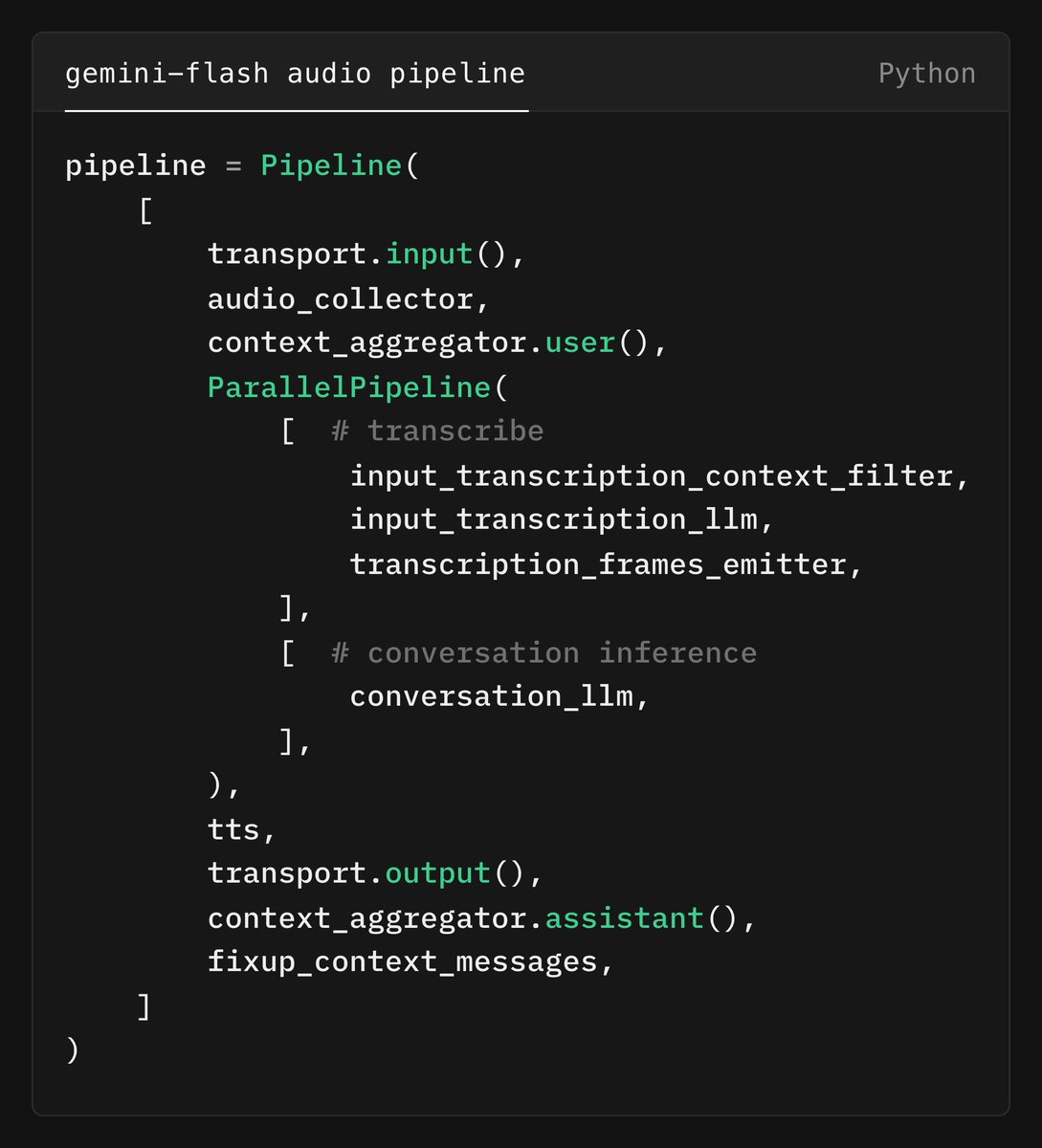
It turns out, though, that it's possible to:
1. Give Gemini user input speech as audio.
2. Then replace that audio chunk with a text transcription, in the conversation history, after it's used the first time.
This gives you almost all the benefit of using native audio, but keeps the conversation history small.
And you can use Gemini itself to do the transcription. So you know that your transcription matches what the model "hears."
Gemini's tokens are so affordable, this is actually quite a bit cheaper than using any of the commercial speech-to-text APIs!
I haven't done a word error rate study, but I stare at transcribed text a lot. Anecdotally, Gemini's transcription is very, very, very good.
Here's the source code of this demo.
https://t.co/7OVfVeDpX8
I played with a few versions of this with structured output, trying to generate both the transcription and the conversational output in a single inference call.
But I never quite managed to write a prompt that was reliable enough, with the structured output approach.
It turned out to be both more reliable (rock-solid reliable) and lower latency to use a ParellelPipeline and two instances of Gemini. Again, Gemini pricing is so good that this turns out to be cheaper than using a traditional speech-to-text service/API.
The latency here from `gemini-1.5-flash-latest` is a respectable 600-800ms.
(For comparison, we generally see 450-650ms from GPT-4o in text mode. But you have to add the text-to-speech time in front of that to have an apples-to-apples comparison.)