November 12, 2024
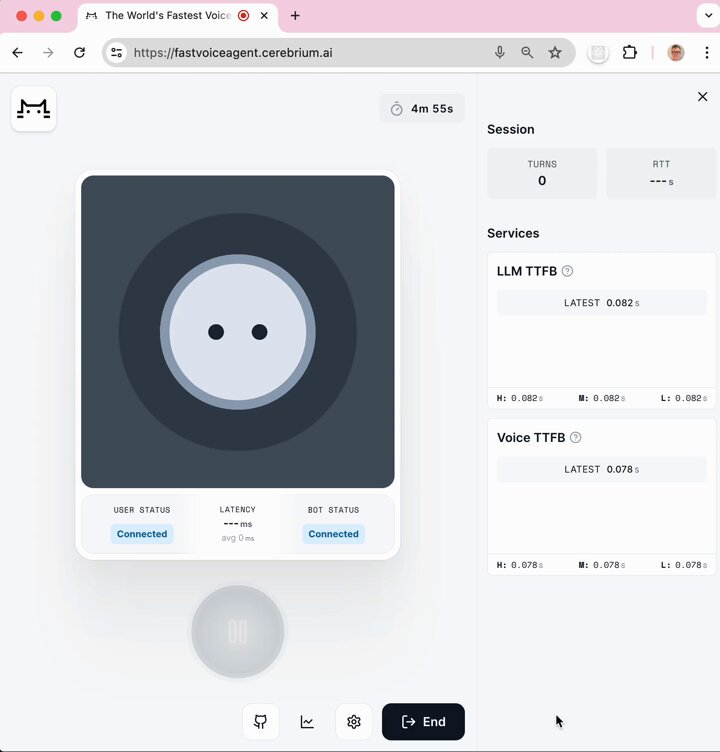
In June we shipped the (then) world's fastest voice AI agent — 500ms voice-to-voice latency including network transport.
The (not-so-) secret sauce behind that demo was @pipecat_ai + @cerebriumai serverless AI infrastructure + @trydaily WebRTC infrastructure.
The team at @cerebriumai is live on Product Hunt today. They've built infrastructure that is super impressive: very fast cold-start times, access to a bunch of different GPUs, support for realtime AI, seamless scaling.
I've learned a *lot* from working them over the past few months on customer-facing deployments and several fun demos.
Go check out what Cerebrium is doing if you're interested in deploying your own AI models and services! -> https://t.co/3WyDezbFHY
As a matter of historical interest, here's the original World's Fastest Voice AI Bot demo and technical write-up:
https://t.co/SYvOi0IjXJ
How to build the world's fastest voice AI bot:
- Self-host speech-to-text, LLM inference, and text-to-speech all together in the same container/cluster.
- Route audio over the internet using WebRTC and edge networking.
- Configure timings for voice activity detection, phrase endpointing, and other parts of the pipeline to optimize for latency. (There are trade-offs to doing this!)
Here's a LLama 3 voice bot that has voice-to-voice response times of ~500ms.
We used @DeepgramAI's STT and TTS for this bot, and everything is hosted on @cerebriumai's serverless GPU infrastructure.