August 23, 2024
Sub-700ms AI video conversational latency 🤯🤯🤯
First, so as not to bury the lede, this is @heytavus's new digital twin API delivering ~670ms latency end-to-end ... from a client application, to the cloud, and back to the client.
That's very, very, very fast. Somewhere between 200-400ms of this is audio/video processing, encoding, and network transport. So Tavus' multi-modal AI stack has a time-to-first-byte here of ~400ms (give or take 100ms). Faster than most LLMs do text-only time-to-first-token!
I'll link to the full video in the next tweet. Across the complete conversation, end-to-end latency averages 1.05 seconds.
But what I really want to show here is how to *actually* measure end-to-end latency for AI apps. Most people get this wrong. (Which is totally understandable. Measuring latency is surprisingly complicated and sometimes non-intuitive.)
You can't just look at the latency of one part of your stack. Your server logs won't give you the whole picture. Even instrumenting request timings from the client isn't going to give you "real" numbers.
What you want to measure is the time delta between:
1. when the user stopped speaking, and
2. the first audio frame from the AI process plays through the device speaker
This measurement needs to include phrase endpointing time, audio processing, playout delay, etc. You can write code in your client app to measure this. It's really fiddly to get it right.
However, there's an easy way to measure "voice-to-voice" latency for any app without writing any code.
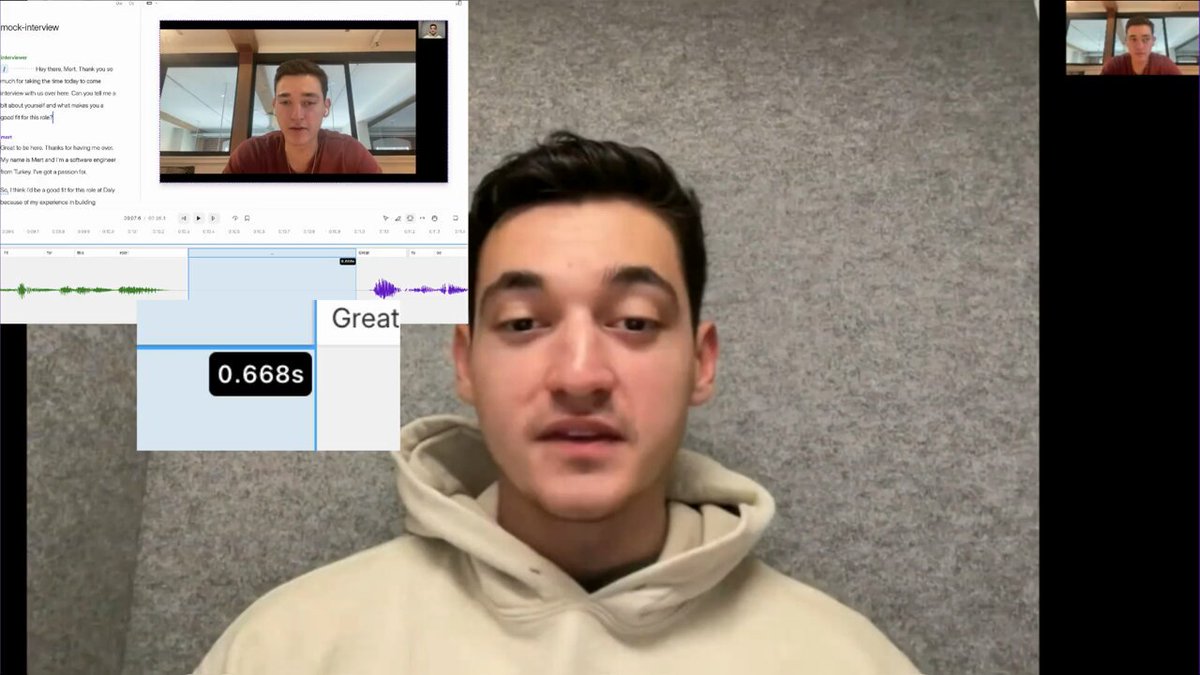
Record a session, then open the recording in an editor that can display audio waveforms. You'll be able to visually see the end of the human speech, and the beginning of the bot speech.
Measure the "quiet period." That's your voice-to-voice latency. You can see this measurement in the short clip attached here.
Here's the full video that I extracted the clip above from[1]
Oh, I also should say: my recommendation for a video editor that's easy to use for this latency measurement is @DescriptApp.
Descript will identify the two different speakers in the video. It will even color-code the audio waveform, which is a nice little visual time-saver if you are measuring the latency of several turns in a conversation.
Funny side note, though. Descript was having trouble correctly attributing the speaking segments in this video clip.
I tried a few times and kept thinking, "What's going on here? Speaker identification in Descript is usually rock solid."
Finally, the penny dropped. This is a "digital twin." It's actually supposed to be the same voice, for some computational definition of "same!"