May 8, 2024
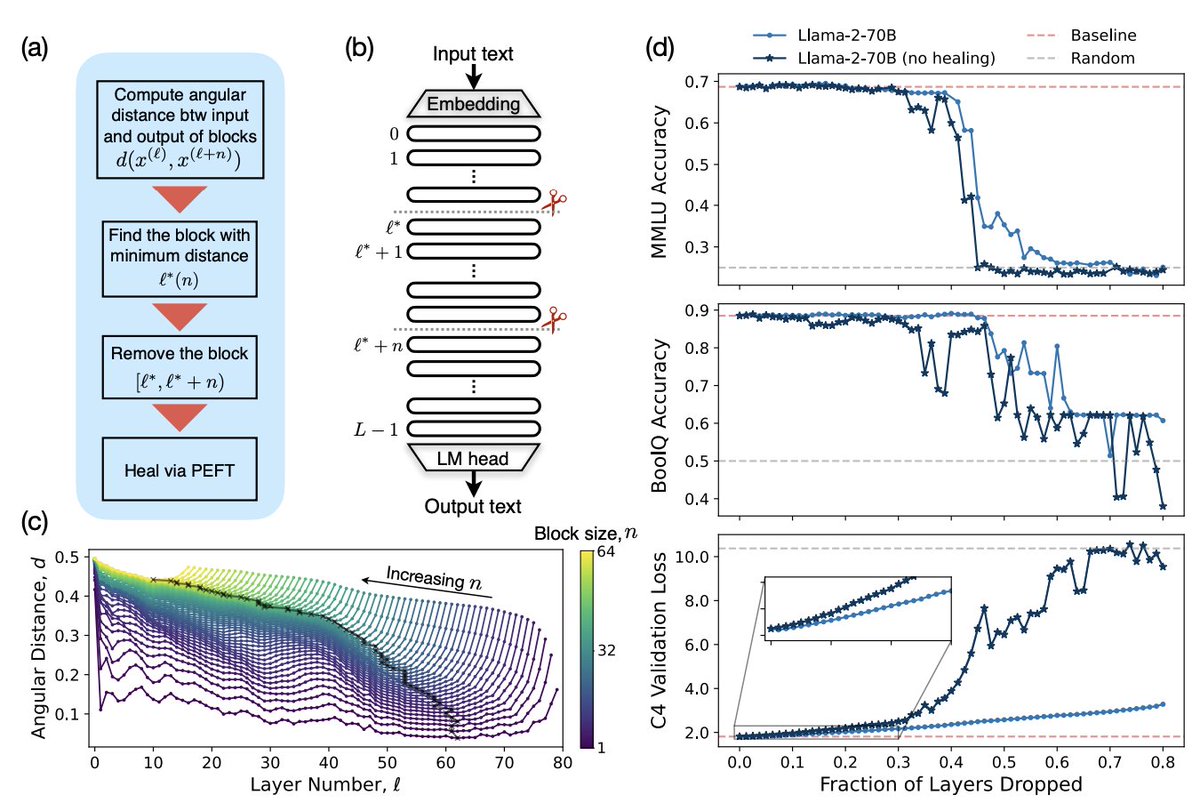
Llama 2 70B in 20GB! 4-bit quantized, 40% of layers removed, fine-tuning to "heal" after layer removal. Almost no difference on MMLU compared to base Llama 2 70B.
This paper, "The Unreasonable Ineffectiveness of the Deeper Layers," was my airplane reading on the way to a conference earlier this week. It's very well written and the results are super interesting.
Delve in here[1]