April 19, 2024
Whoah. Llama-3 70 time-to-first-byte on @GroqInc is very fast — sub-100ms fast.
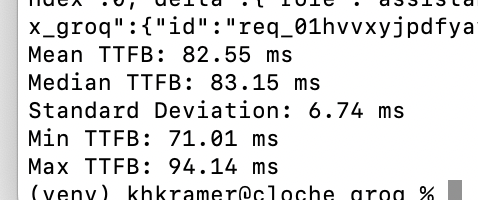
As always these days, I asked the model to write me a little Python script to benchmark the model. Llama-3 70B definitely didn't get the script right in one shot. But also, I didn't put any effort into the prompt and this is the kind of prompt that today's models aren't very good at — at least with lazy prompting! I did find the initial script that the model produced to be a helpful starting point, though.
Here's the benchmark script: https://t.co/ztwWQIB2Nw
The same test with gpt-4-turbo shows an ~800ms time-to-first-byte.
(All the usual caveats about quick and dirty benchmarks apply here!)